计算机体系结构
导航
- 导航
- 成绩构成
- Fundamentals of Computer Design
- chpater2–Memory Hierarchy
- chapter3–dynamic parallelism
- chapter4–
成绩构成
- 作业加实验加考试。
- 实验尽早完成(三周以后得分可能会下降,两周内完成较好),可能会有bonus。
Fundamentals of Computer Design
Introduction
- 体系结构=指令集+实现指令集
chpater2–Memory Hierarchy
Introduction of memory
- 存储器层次结构:
- register->cache->main memory->disk
- 离cpu越近,越小,访问速度越快
- 两个设计关键点:
- 时间局部性
- 空间局部性
Technology Trend and Memory Hierarchy
four questions for cache design
- 见计组笔记
Block replacement
- Lru本质上是stack replacement algorithm
- $B_t(n)$ represents the set of access sequences contained in a cache block of size n at time t.
- $B_t(n)$ 是 $B_t(n+1)$的集合,也就是n增大,命中的块一定包含原来的块,也就是说命中率会上升。
- FIFO本质上是队列replacement algorithm
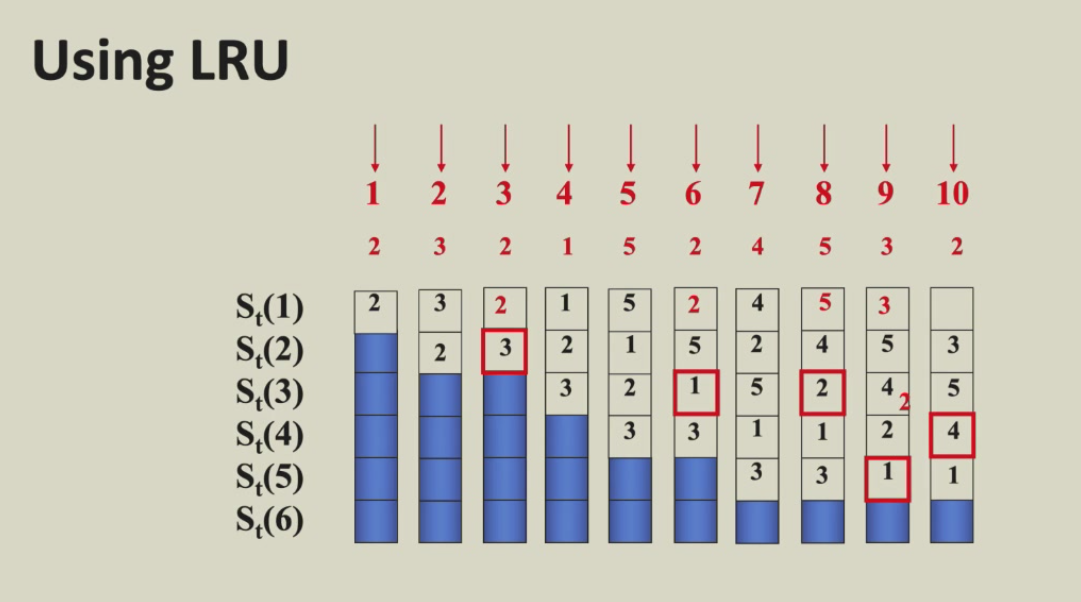
解释:我感觉这张ppt的图很棒,很巧妙地使不同大小的block对于同一个sequence采用lru策略的结果放在了同一张图中。用栈来模拟LRU,栈顶是最近访问的,栈底是最久未访问的。
- 使用门和触发器实现LRU算法
- 让任何两个cache块之间两两结对,用一个触发器的状态来代表两个块的先后访问顺序(比如1表示A刚被访问,0表示B刚被访问)。通过门电路对触发器的状态进行逻辑组合找到LRU块。
- 假设有p个cache blocks,我们需要$\binom{p}{2}=p * (p-1)/2$
write policy
- 对于write miss
- write around(no write allocate)
- 直接在内存中写
- write allocate
- 将写的块读在缓存中再写
- write around(no write allocate)
- 对于write hit
- write through(通常和write around搭配)
- 同时写回cache和内存
- write back(通常和write allocate搭配)
- 直接在cache中写,并标记为赃块
- write through(通常和write around搭配)
Memory system performance
Virtual Memory
chapter3–dynamic parallelism
dynamic vs static
- 根据branch的历史数据来预测
- 使用branch prediction buffer indexed by lower portion of branch address and 使用一位来表示taken/untaken status(bit 1 for taken,bit 0 for untaken)
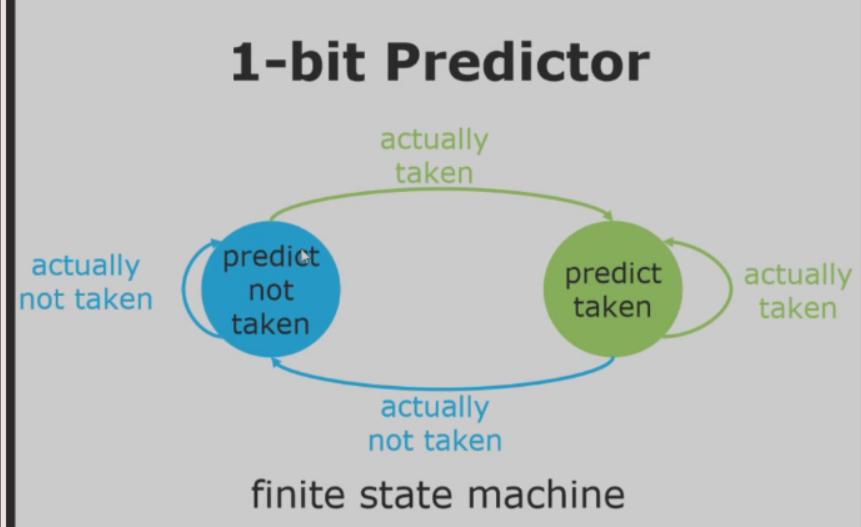
1-bit predictor
- 状态机如下(利用历史数据来预测)
![tixi1]()
- 在循环中使用1-bit predictor时,因为在循环中我们的选择肯定是连续相同的,则预测会非常准确。
- 然而如果是摇摆的,有可能会导致预测率相当低,远不如静态预测。
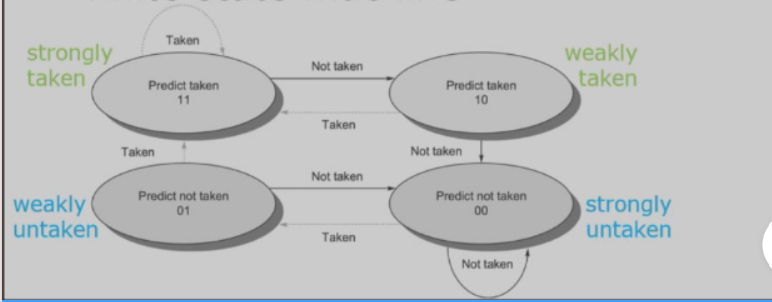
2-bit predictor
- 状态机如下(利用历史数据来预测)
![tixi2]()
- 在摇摆情况下,预测率会更高,达到50%。
- 我们可以再进行泛化到n-bit,只是存储开销更大
generalized to local history
- 前面提到的predictor其实都是在考虑前一天的预测,我们可以考虑更多的天数
correlating predictor
- 这也叫做二级预测器,例如(1,2)预测器在预测一个分支时,利用最近一个分支的行为在一对二位分支预测器中选择。一般情况下(m,n)预测器利用最近m个分支行为在$2^m$个分支预测器中选择,其中每一个分支预测器都是n位。
- 一个(m,n)预测器的位数:$2^mn$由分支地址选中的预测项的数量
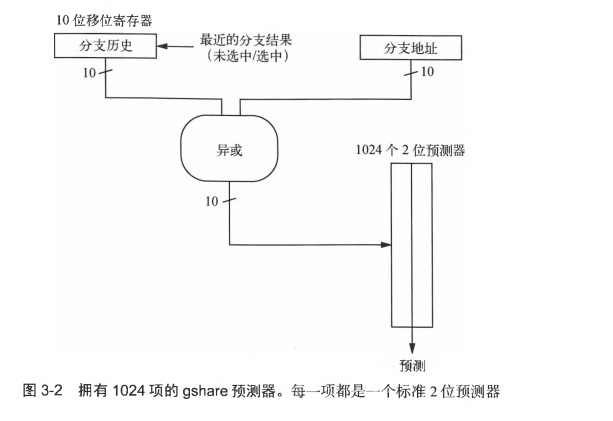
- 相关预测器的一个著名例子就是gshare预测器,
![tixi3]()
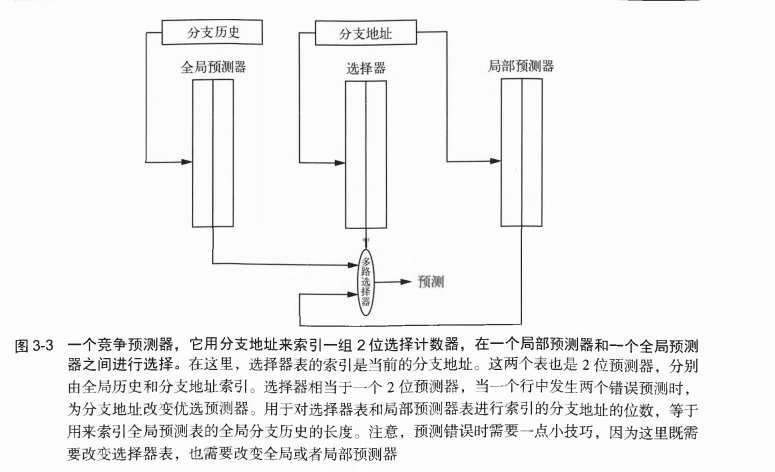
tournament predictor
- 通常使用一个全局预测器和一个局部预测器。全局预测器使用最近的分支历史作为预测器的索引,局部预测器使用分支地址作为索引。
- 一个例子
![tixi4]()
dynamic sheduling overcome datahazard
动态调度的思想
- 想要成功实现动态调度,我们仍然使用顺序指令发射,但我们希望一条指令能够在其数据操作数可用时立即开始执行,这样的流水线实际是乱序执行(out-of-order execution)
- 但是乱序执行可能导致WAR冒险和WAW冒险:(利用寄存器重命名可以解决)
1 | |
为了能够乱序执行,我们将简单的五级流水线ID分成两个阶段(发射、读取操作数)。
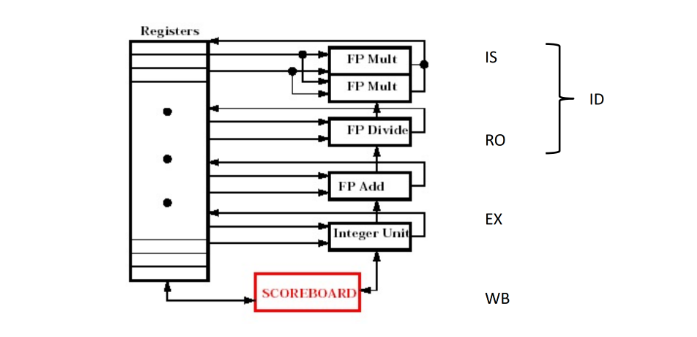
记分牌技术:
- 结构(注意有两个乘法部件):
![tixi5]()
- 例子:
1
2
3
4
5
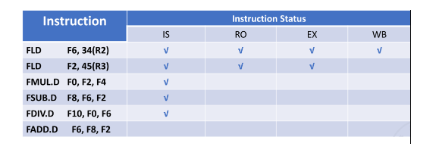
6FLD F6, 34(R2)
FLD F2, 45(R3)
FMUL.D F0, F2, F4
FSUB.D F8, F2, F6
FDIV.D F10, F0, F6
FADD.D F6, F8, F2- instruction status
![tixi6]()
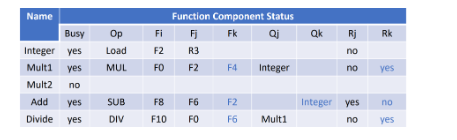
解释:指令1已经执行完成,scoreboard没有其信息。指令2没有完成WB,后面的指令要使用指令2的结果,由于数据冒险所以还没有进行读取操作数阶段。指令6是加法操作,此时存在结构冒险还没有进入发射阶段。 - Function Component status
![tixi7]()
解释:busy代表当前这个单元是否有指令正在使用,op表示这个单元正在被哪类指令使用。Fi,Fj,Fk代表源操作数和目的操作数(Fi为目的操作数)。Qj,Qk表示表示源操作数来自哪个部件。Rj,Rk表示源操作数的状态(注意当指令正在执行时,源操作数的状态为no)。 - 在scoreboard算法中,只要我们成功过了op阶段,那么多条成功经过op阶段的指令都能并行执行,这样相比较传统的流水线也有大幅度提升。
- 总结工作要点:
- 一条指令能否发射,一看是否有功能部件空闲可用,这个信息包含在功能状态中;二看指令要写的寄存器是否正要被别的指令写,这个信息包含在寄存器状态中,观察这个信息是为了解决 WAW 冒险。
- 一条指令能否读数,要看记分牌是否提示源寄存器不可读,如果不可读,就说明该寄存器将要被别的前序指令改写,现在的指令要等待前序指令写回,观察这个信息是为了解决 RAW 冒险。
- 一条指令能否写回,要看是否有指令需要读即将被改写的这个寄存器,具体一点来说,就是要观察标记 Yes 的Rj、Rk 对应的寄存器里是否有当前指令的目的寄存器,如果有,就说明有指令需要读取寄存器的旧值,这样一来我们就要等指令读完旧值之后再写回,观察这个信息是为了解决 WAR 冒险。
- 所以本质上以上三种数据冒险,记分牌的策略都是通过阻塞解决。
- 结构(注意有两个乘法部件):
Tomasulo Algorithm
scoreboard并不能解决WAR和WAW这两个冒险(源于名称依赖),只是单纯的通过阻塞解决。
理解寄存器重命名如何消除冒险
- 代码示例
1
2
3
4
5fdiv.d f0,f2,f4
fadd.d f6,f0,f8
fsd f6,0(x1)
fsub.d f8,f10,f14
fmul.d f6,f10,f8- 我们现在考虑三个名称依赖:fadd.d使用f8时的WAR冒险,fsub.d使用f8时的WAR冒险(写后读,反依赖:两条指令共享同一个存储位置),fadd.d可能在fmul.d之后完成导致的WAW冒险(输出依赖)。
- 这三个名称依赖都可以通过寄存器重命名消除。假定存在两个临时寄存器:S和T。
1
2
3
4
5fdiv.d f0,f2,f4
fadd.d S,f0,f8
fsd S,0(x1)
fsub.d T,f10,f14
fmul.d f6,f10,T保留站
- 保留站在一个操作数可用时马上提取并缓冲它,这样就不需要从寄存器中获取操作数,这也就意味着我们的相应的数据进入保留站后数据直接拷贝而不依赖于寄存器(因为记分牌的数据还一直依赖于寄存器),这样tomasulo利用保留站就能很好地避免因为“假依赖”导致阻塞,从而提高效率。
- 发射指令时,会重命名待用操作数的寄存器说明符,改为提供寄存器重命名功能的保留站的名字。
寄存器状态表
- 指令在发射的时候会更新寄存器状态表,如果后序指令和前序指令的目的寄存器重合了,就用后序指令的写信息标志寄存器,表示只会把后序指令的计算结果写进寄存器,这样可以解决写后写冒险;
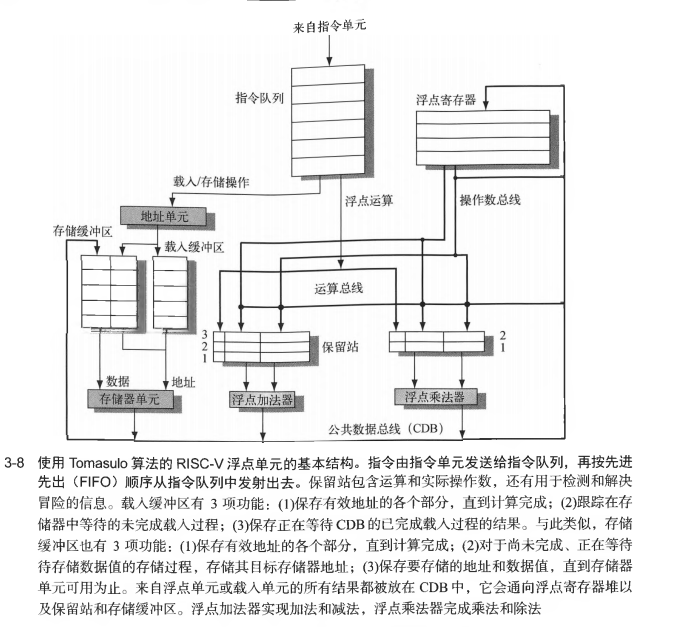
使用Tomasulo算法的浮点单元基本结构
![tixi8]()
每一条指令经历的步骤
- 发射阶段:从指令队列的头部获取下一条指令,如果有一个匹配的保留站为空则将这条指令发射到这个站中。如果没有空闲保留站则说明存在结构冒险,该指令停顿。如果操作数不在寄存器中,则一直跟踪将生成这些操作数的功能单元。并且在这一阶段对寄存器进行重命名。
- 执行:如果还有一个或多个操作数不可用,则在等待计算的同时观察公共数据总线。当一个操作数变为可用时,就将它放到任何一个正在等待它的保留站中。当所有操作数可用时,则在功能单元执行运算。
- 写结果:在计算出结果后,将其写到CDB上,再从CDB传送到寄存器和所有等待这一结果的保留站。存储指令一直缓存在存储缓冲区中,直到待存储值和存储地址可用为止,然后在有空闲存储器单元时立即写入结果。
tomasulo算法的实例
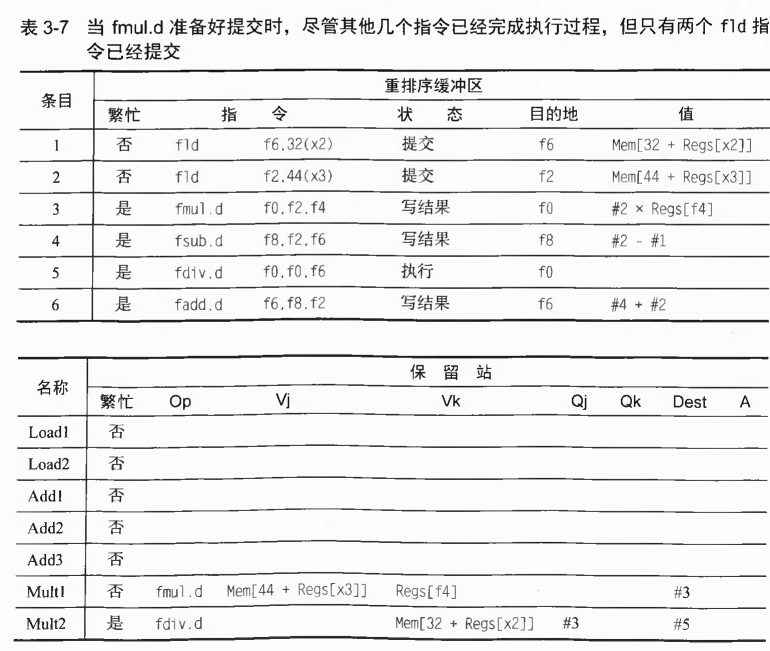
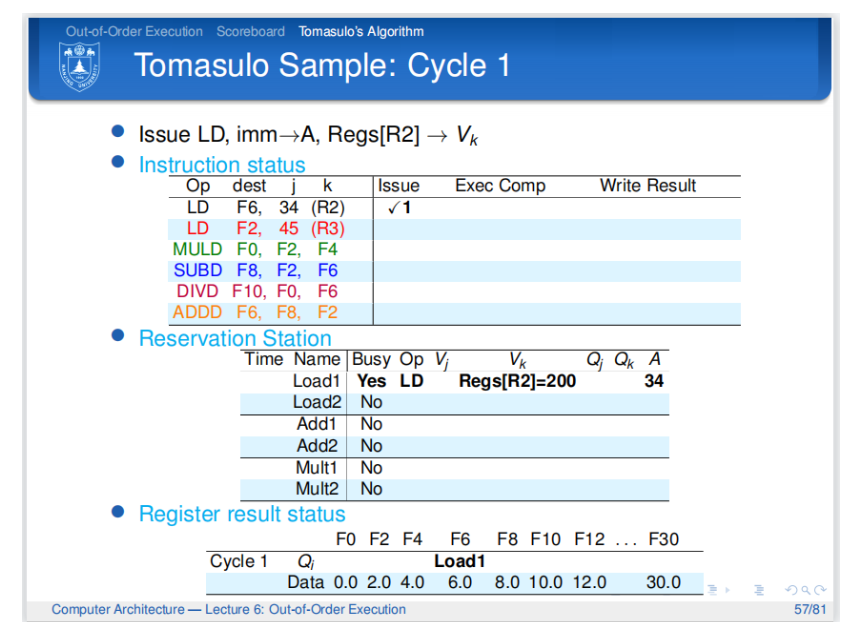
- cycle1:
![tixi9]()
解释:在第一个周期,第一条指令发射到保留站中,并且保留站的信息更新(注意此时的Vk与记分牌不同,直接从寄存器堆中拷贝数据,A是地址偏移立即数).寄存器结果状态也相应地更新。 - cycle2:
![tixi10]()
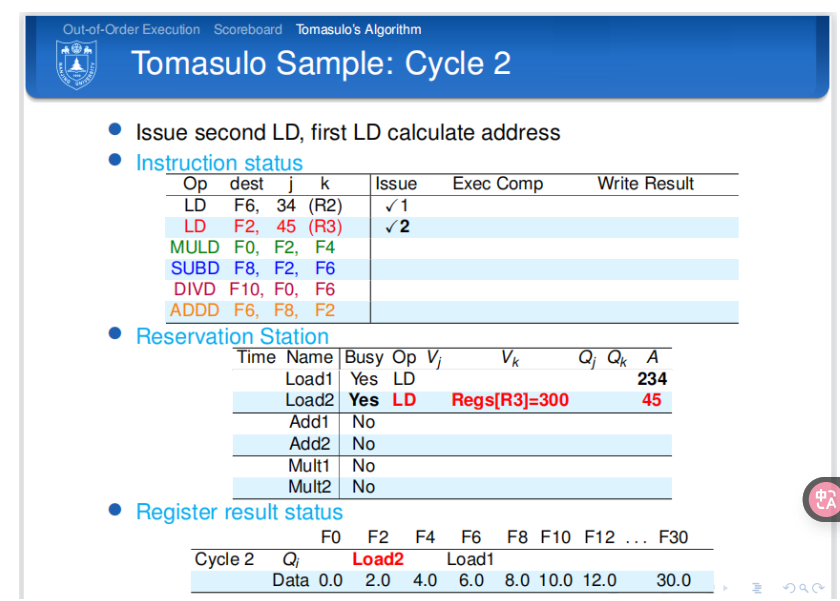
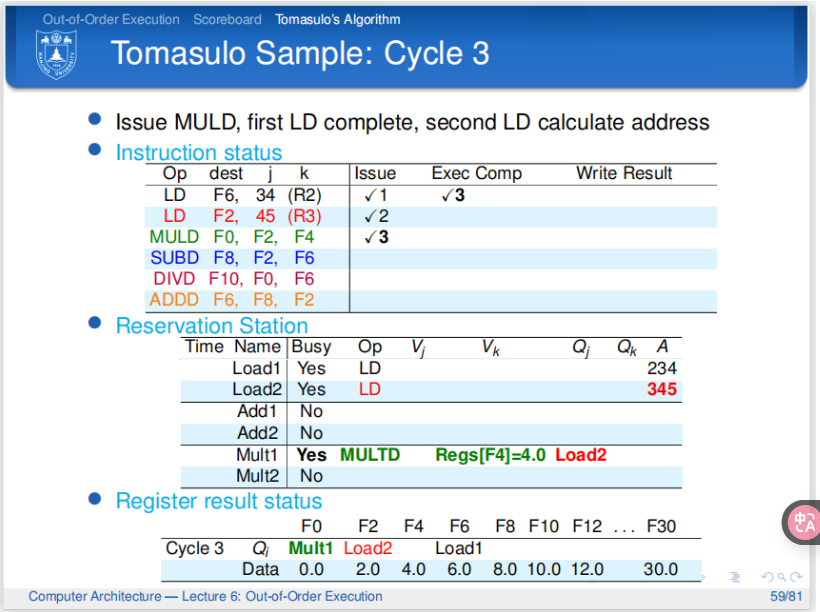
解释:第二个周期,第二条指令发送到保留站,此时第一条指令刚刚执行完偏移量的计算并更新相应的A. - cycle3:
![tixi11]()
解释:第三个周期。第三条指令发送到保留站中。第一条指令执行完毕执行过程。第二条指令完成偏移量的计算并更新相应的A。寄存器结果状态完成相应的更新。 - cycle4:
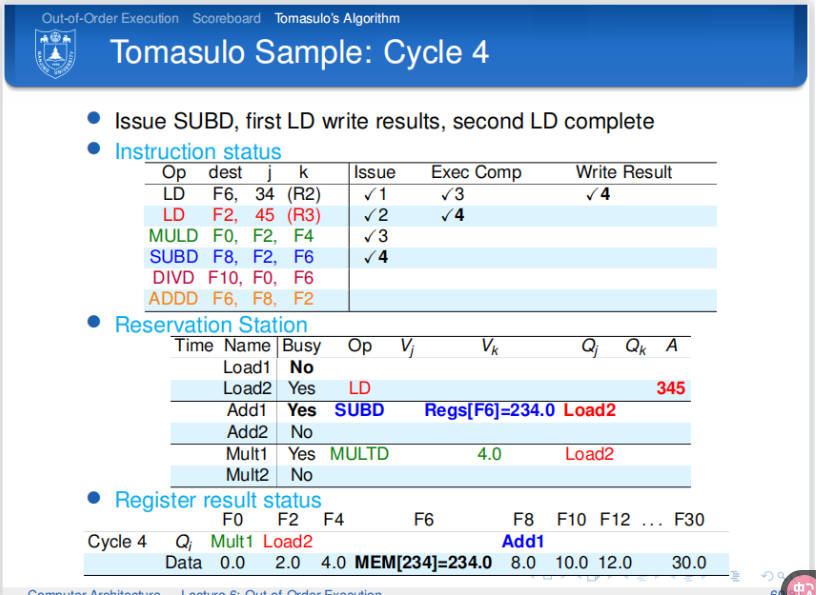
![tixi12]()
解释:第四个周期结束。第一条指令完成写回阶段,此时结果立马传递到CDB,然后CDB立马传递到相应的寄存器中。第二条指令执行完毕执行过程。第三条指令因为还需要第二条指令的结果所以被阻塞。第四条指令发送到保留站,此时发现第四条指令的相应的保留站中的寄存器的值已经是最新的值。 - cycle5:
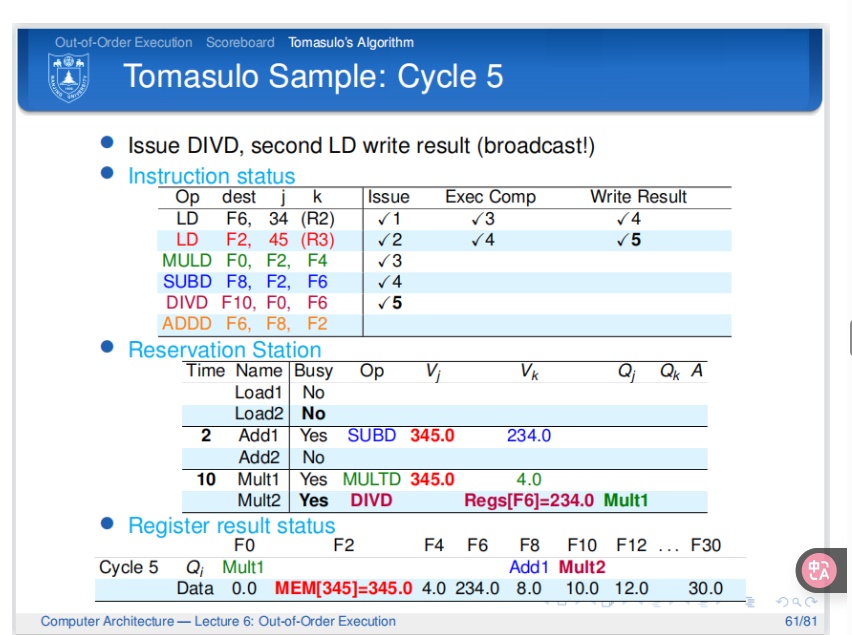
![tixi13]()
解释:第五个周期结束。第二条指令完成写回阶段。此时第三条指令和第四条指令都同时从CDB中获取到寄存器的值。并且更新这两条指令需要执行的周期数(更新在Time中,从下一周期开始执行阶段)。第五条指令因为保留站有空余于是发射到保留站中。
- cycle1:
Hardware-Based speculation
- 因为前面的无论是scoreboard还是tomasulo算法,我们得到结果以后都直接将最终结果写入了寄存器,所以是乱序提交的。
- 但是我们从动态调度中延伸到推测,因为使用旁路值类似于执行一次推测寄存器读操作,所以我们现在的寄存器的值必须确保是正确的值,所以有了我们接下来的操作。
- 我们使用Reorder Buffer来使指令执行完成的顺序也是顺序的。结果先写到reorder buffer中,再从reorder buffer中取到结果,写入到寄存器中。我们将每条指令加上一个commit状态,对于某条指令,只有它前面的指令都commit,它才能commit。
- Hardware-based speculation combines three key ideas:
- dynamic branch prediction to choose which instructions to execute
- speculation to allow the execution of instructions before the control dependences are resolved (with the ability to undo the effects of an incorrectly speculated sequence)
- dynamic scheduling to deal with the scheduling of different combinations of basic blocks
Tomasulo and extended to handle speculation
- Issue:get instruction from FP Op Queue
- Execution
- Write result
- 在与该指令相关的操作完成到该指令提交之间,ROB保存该指令的结果。
- ROB是指令的操作数来源,就像Tomasulo算法中的保留站提供操作数一样。
- Commit:update register with reorder result
- 实现speculation背后的关键思想是允许指令乱序执行,但强制它们按顺序提交,并防止任何不可撤销的操作(如更新状态或获取异常),直到指令提交。
- 重新排序缓冲区(ROB)以与Tomasulo算法中的保留站扩展寄存器集相同的方式提供额外的寄存器。
- 在这种进化版的tomasulo,保留站也发生了变化(Qj,Qk字段以及寄存器状态字段中的保留站编号被ROB条目编号代替,以及将Dest字段加到保留站中,Dest指定的是保留站条目产生的结果在ROB中的目的地)

ROM与保留站: