

计算机组成
chapter2 instructions:language of the computer
2.1 introduction
2.2 operations of computer hardware
算术
ex
1 | |
2.3 operands of computer hardware
64-bit data call doubleword
32-bit data call word
Risc-v 有32个64位寄存器
Risc-V 是小端模式(小端模式下,数据的低位存储在低地址,高位在高地址;而大端模式则相反,高位存储在低地址。在读取数据时,无论哪种模式,都是从低地址开始)即这个word的第0个byte放在最低的位置(least address of a word)
Risc-V 不需要aligned
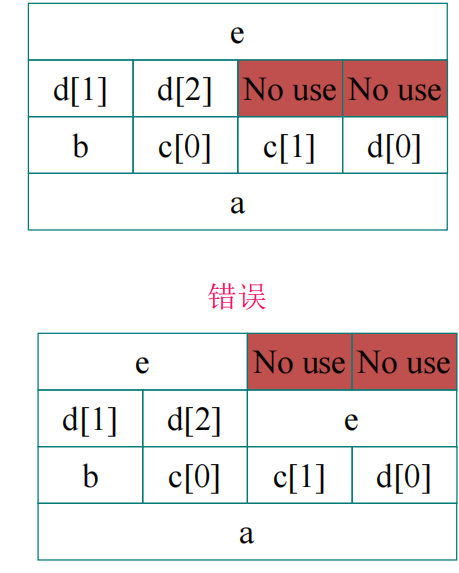
- 下面举一个memory的Risc-V编译例子

解释:ld和sd是对memory的指令,其中的数字代表对应的地址。
register和memory
- Registers are faster to access than memory
- 进行操作时将memory load到register或者被store
- Compiler must use registers for variables as
much as possible
make common case fast
- 对于常见的命令,例如immeidate add,当我们把它们变作一个命令以后,就舍去了load操作,大大提升了编译时间。
2.4 有符号数和无符号数
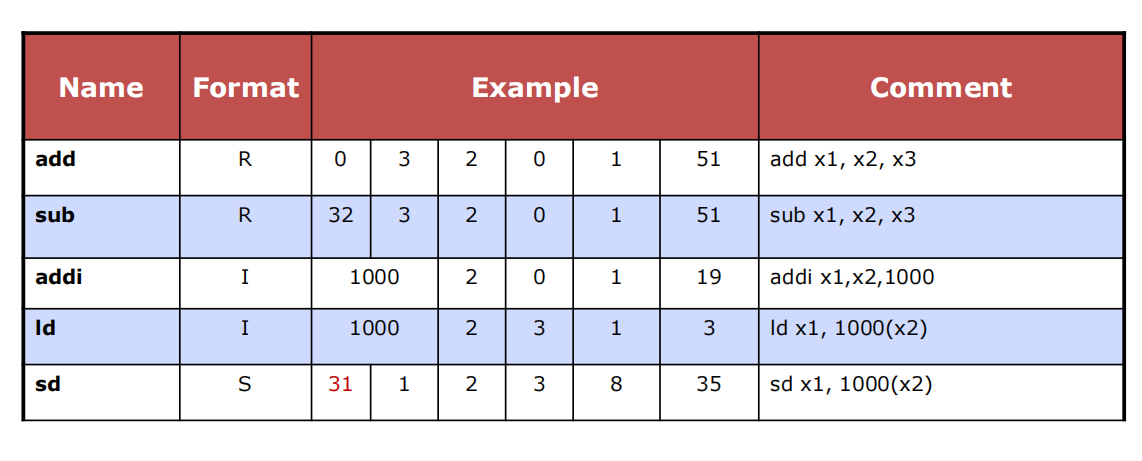
2.5 representing instructions in the computer
- 指令在计算机中的表示方法(如下例)

这个表示方法就是RISC-V R-Format:
funct7(7 bits) rs2(5 bits) rs1(5 bits) funct3(3 bits) rd(5 bits) opcode(7 bits)
但是有些指令的相关寄存器只有两个(Risc-V I-Format Instructions)
immediate
encoding
format
- 解释:sb指令与UJ指令的immed的特殊位置排序的原因:功能不同并且尽可能多地位数相互对应。
2.6 logical operations
shift operations
- I-format 但是immediate只有六位(因为能够最多表示移63位已经满足所有情况
若是logical对应的immediate操作
- 因为我们的寄存器处理的数据为64位,但是immeidate为12位,所以对immediate作有符号数扩展
2.7 instructions for making decisions
branch
- branch instructions
beq register1,register2,L1(若==则执行)
bne register1,register2,L2(若!=则执行)
loop

- 解释:首先进行读取,因为是double word所以每次的地址都是i乘上8,所以在开头进行移位操作(解释一下A[i]的地址占据应该为[8i+7:8i])。再加上最初的A[0]地址算出A[i]地址,利用地址进行load操作(需要注意在这里因为已经是A[i]的地址所以我们load前面的immediate操作数为0),接着进入判断条件,若满足进入循环。
most popular compare operand
slt
If the first reg. is less than second reg. then sets third reg to 1
slt x5,x19,x20(x5=1 if x19 < x20)more conditional operations
blt rs1, rs2, L1
if (rs1 < rs2) branch to instruction labeled L1
bge rs1, rs2, L1
if (rs1 >= rs2) branch to instruction labeled L1signed and unsigned
Signed comparison: blt, bge
Unsigned comparison: bltu, bgeu
jump register
- jalr
jalr rd,imm(rs1)
解释:rd是要保存返回地址的目标寄存器。
rs1是包含要跳转到的地址的源寄存器。
imm是一个偏移量,用于相对于rs1寄存器的计算(可选字段)。
2.8 supporting procedures in computer hardware
procedure call instruction
instructions of procedure
- jal x1,procedureaddress(UJ)
跳转到绝对的地址,同时将返回地址(PC+4)保存到寄存器
Address of following instruction put in x1
Jumps to target address
procedure return
- jalr x0,0(x1)(I)
跳转到一个寄存器中指定的地址,同时将返回地址保存到寄存器
Like jal, but jumps to 0 + address in x1
Use x0 as rd (x0 cannot be changed)
Can also be used for computed jumps
Using more registers
在后面的RISC-V规定中会提及:
通常题目会说堆栈的指针要在16的倍数上对齐,意味着我们每次操作都至少要将sp移动16个字节。
采用堆栈操作
push:sp=sp-8
pop:sp=sp+8example

- sp在压栈前应该指向最后一个word(而不是下一个空的word(课堂上大家最终达成了共识))
RISC-V规定
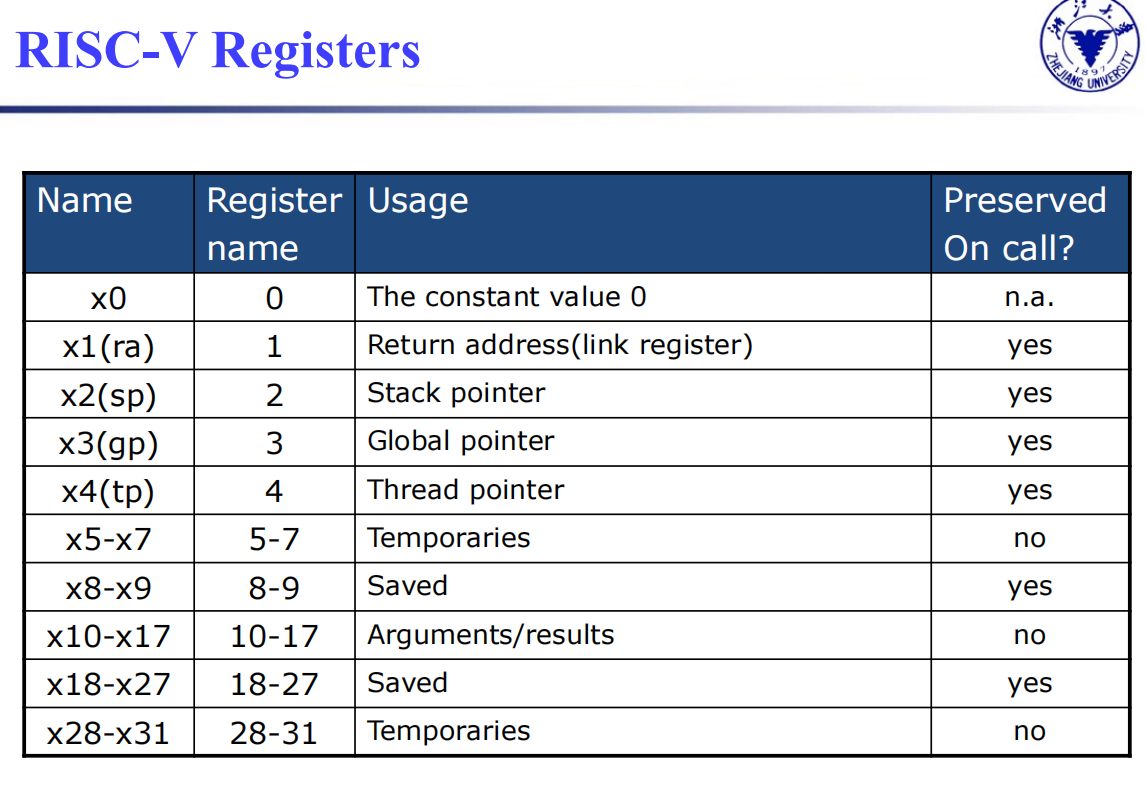
- x0为常数0,这个一定要切记
- x5 - x7 以及 x28 - x31 是 temp reg,如果需要的话 caller 保存;也就是说,不保证在经过过程调用之后这些寄存器的值不变。
- x8 - x9 和 x18 - x27 是 saved reg,callee 需要保证调用前后这些寄存器的值不变;也就是说,如果 callee 要用到这些寄存器,必须保存一份,返回前恢复。
- x10 - x17 是 8 个参数寄存器,函数调用的前 8 个参数会放在这些寄存器中;如果参数超过 8 个的话就需要放到栈上(放在 fp 上方, fp + 8 是第 9 个参数, fp + 16 的第 10 个,以此类推)。同时,过程的结果也会放到这些寄存器中(当然,对于 C 语言这种只能有一个返回值的语言,可能只会用到 x10 )。
- x1 用来保存返回地址,所以也叫 ra 。因此,伪指令 ret 其实就是 jalr x0, 0(x1) 。
- 栈指针是 x2 ,也叫 sp ;始终指向 栈顶元素。栈从高地址向低地址增长。
addi sp, sp, -24 , sd x5, 16(sp) , sd x6, 8(sp) , sd x20, 0(sp) 可以实现将 x5, x6, x20 压栈。 - 一些 RISC-V 编译器保留寄存器 x3 用来指向静态变量区,称为 global pointer gp 。
- 一些 RISC-V 编译器使用 x8 指向 activation record 的第一个 dword,方便访问局部变量;因此 x8 也称为 frame pointer fp 。在进入函数时,用 sp 将 fp 初始化。
fp 的方便性在于在整个过程中对局部变量的所有引用相对于 fp 的偏移都是固定的,但是对 sp 不一定。当然,如果过程中没有什么栈的变化或者根本没有局部变量,那就没有必要用 fp 了。
Nested procedures
ex
1 | |
现在我们研究上述c语言的risc-v指令
解释:我们首先要建立这样一个大概,在没有进行到底部时a0(参数)与ra(函数调用地址)不断被压栈保存。当递归到底部时,我们开始jarl zero,0(ra)开始回到上一个函数调用(因为注意当我们之前在L1中操作时命令jal ra,fact中的ra保留的是这一条指令的下面指令的位置,即开始进行L1的后半部分),不断更新a0(即结果),然后将栈pop得到上一个函数地址再进行jarl zero,0(ra)
- 类似于这种将递归转化为risc-v其实有两种写法,一种是上面的写法在调用过程中跳转到另一个分支,另一种是在尾部才跳转到另一个分支。()
1 | |
- 斐波拉契数列同样地利用尾部跳转到另一个分支(但是可以注意到的是,如果我们把fib中的最后一行去掉其实没有问题,因为程序会顺序执行(PC+4)也就是done。)
1 | |
loacl data on the stack
- fp与sp两个指针
- fp在一次函数调用的储存中固定,而sp随着压栈的元素不断移动.即fp只指向这个进程的起始位置
2.9 communicating with people
string copy


- 因为这个例子是一个leaf procedure所以有优化的点
- For a leaf procedure
The compiler exhausts all temporary registers
Then use the registers it must save
2.10 对大立即数的RISC-V的编址和寻址
32-bit constants
- 当我们load时,要进行两次操作,先将前20位load进去,再加上后12位
- 但是后12位需要扩展到32位,当后12位的符号位为1,则前面都需要扩展为1,那么我们第一次20位就需要做出一点变化。
![32bit]()

branch addressing
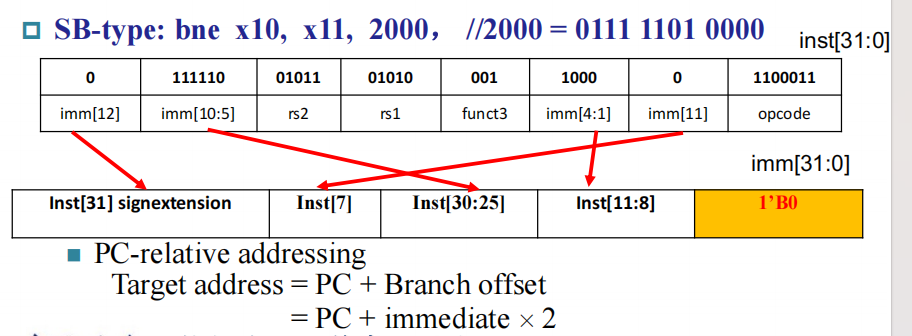
有些题目可能会遇到计算pc端的可能的地址,因为我们储存的特殊性,所以对于sb指令而言,正向只能至多移动(4094),但是负向可以至多移动(-4096)
对于bne指令,是SB类型,则imm[12]是符号位,而imm[0]默认为0,相当于跳跃时只能跳转偶数操作,这也与我们后面的指令地址以halfword对齐照应。
PC-relative addressing
Target address = PC + Branch offset
= PC + immediate × 2 即通常存储的是相对位置,这也与下面的一个例子相互对应
jump addressing
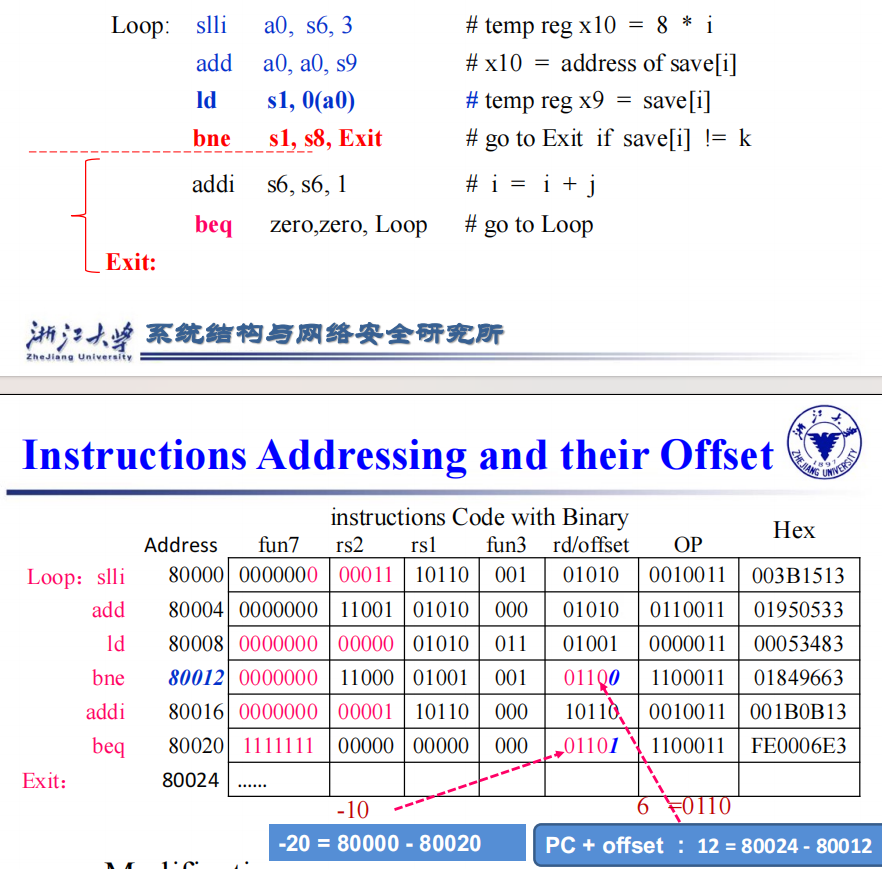
- 解释:All RISC-V instructions are 4 bytes long
PC-relative addressing refers to the number of halfwords
The address field at 80012 above should be 6 instead of 12 - 但是其实你仔细研究上面的代码,会发现如果加上我们默认的imm[0]=0,其实蕴含的imm的距离就是12和-20,也就是imm其实就是代表两条指令的地址的字节差。
指令类型对应寻址方式
- immediate addressing addi x5,x6,4
- register addressing add x5,x6,x7
- base addressing ld x5,100(x6)
- PC-relative addressing beq x5,x6,L1
2.11 指令与并行性:同步
risc-v中的同步
Load reserved: lr.d rd,(rs1)
Load from address in rs1 to rd
Place reservation on memory addressStore conditional: sc.d rd,(rs1),rs2
Store from rs2 to address in rs1
Succeeds if location not changed since the lr.d Returns 0 in rd
Fails if location is changed Returns non-zero value in rd上述两条指令的例子
![lock]()

2.12 translating and starting a programme
2.13 A C sort example to put it all together
2.14 arrays vs pointers

解释:上述例子就是数组和指针两种方式进行清空一个数组操作,只是数组的操作通过i来控制每次i加1,再进行移位操作;而指针直接找地址,每次地址加8。
chapter3 arithmetic for computers
3.1 introduction
- there are 32bit/word(默认) or 64bit/word in RISC-V
- 数的表示二进制,有符号数与无符号数
3.2 arithmetic
addition and subtraction
- 加减法可以直接使用补码进行操作,但是乘法不能
overflow
- 次高位向最高位有进位,最高位上去没进位或次高位向最高位没进位,最高位上去有进位(即异或操作)
则会发生溢出(前提都是考虑补码操作) - 应对措施:忽略;在alu操作检测
construct an alu
- extended the adder
- build a single
- expand it to the desired width
- 添加comparison操作
slt rd,rs,rt(32位寄存器)
n If rs < rt, rd=1, else rd=0
n All bits = 0 except the least significant
alu总体设计
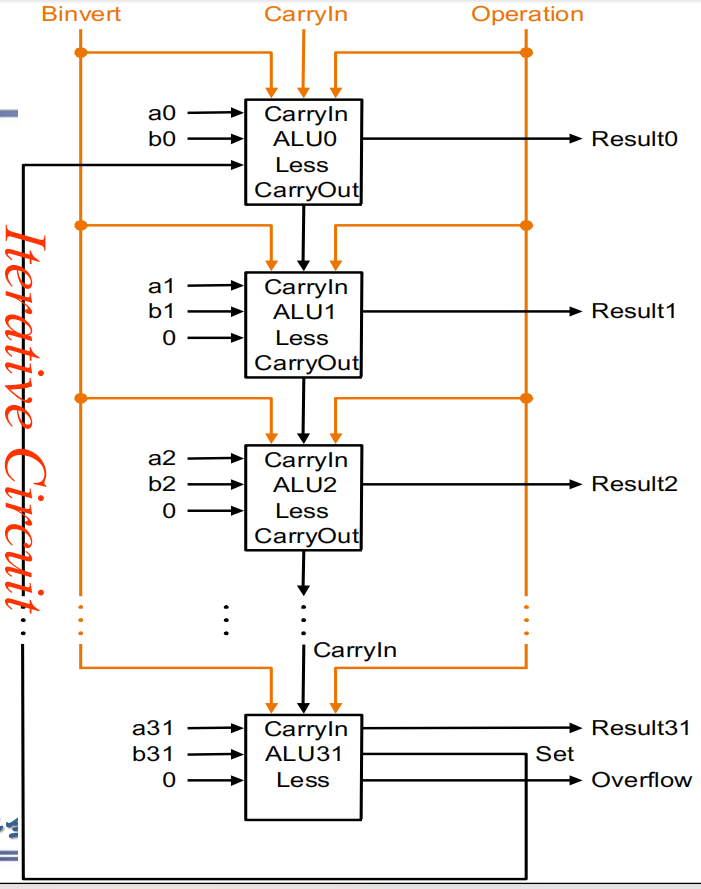
需要注意:Less 和 Set 共同使用,是为了实现 slt rd, rs1, rs2 这个操作(即实现比较操作)(SLT 即 Set Less Than)的。这个操作的含义是,如果 rs1 < rs2 ,那么将 rd 置为 1 ,否则置为 0 。如何进行这一判断呢?很简单,rs1 < rs2 即 rs1 - rs2 < 0,也就是说如果 rs1 - rs2 结果的最高位是 1 ,那么就说明 rs1 < rs2 。所以对于 slt 这个操作,我们只需要计算 rs1 - rs2,而后将 ALU63 中加法器的结果(即最终结果的符号位)赋值给 Result[0] ,即运算结果的 Least Significant Bit,而将其他位的结果 Result[1:63] 都设成 0,就可以完成 slt 操作了。
- 常见的alu选择数对应的功能如下
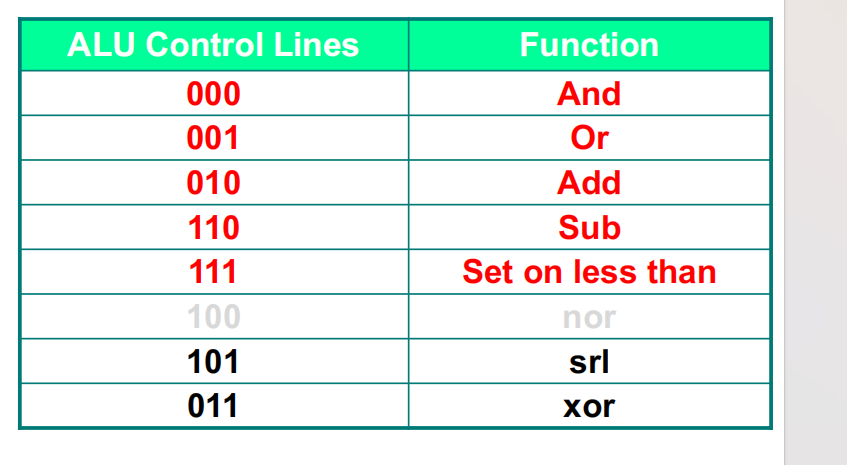
verilog设计
- 检测overflow:增加一位观察其位数,并根据alu operation再根据原来的a和b的最高位三者
进行综合来判断是否发生溢出。
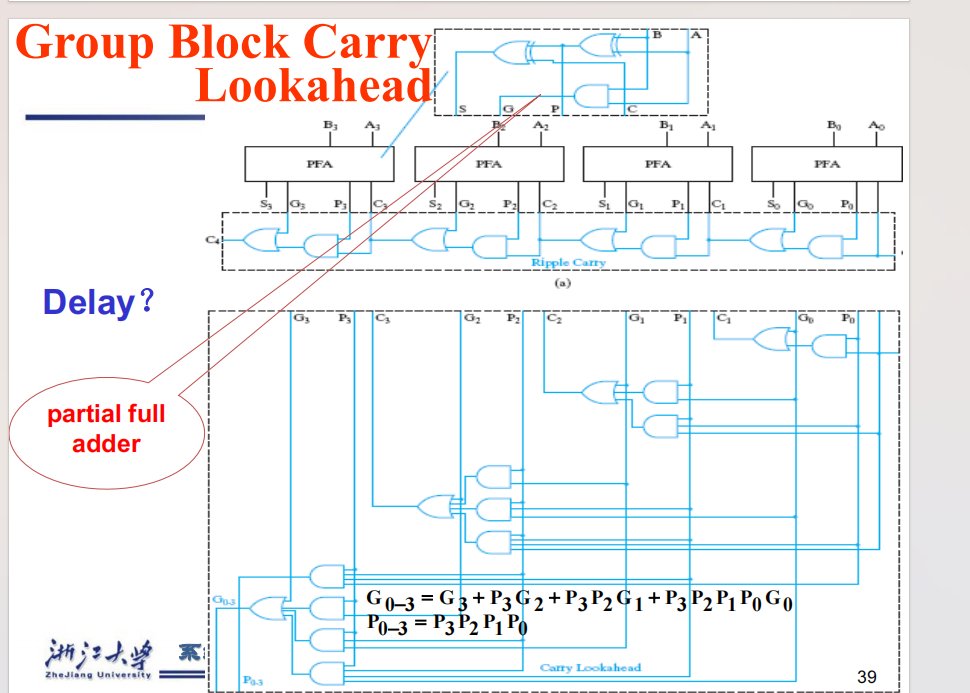
更快的方法
超前进位加法器
思路:对于普通加法器而言,运行缓慢的重要因素是因为在我们进行计算的时候,我们需要等待前面的部件
计算完成产生进位后再来计算。而超前进位加法器则是通过假想所有进位可能产生的情况,提前对每一位进行
与操作和或操作,大大减少了进行加法需要的时间![chaoqian]()
详细的数学推导如下
![chaoqian2]()
如果想要将运算的位数扩展为16位即原来的四倍,一种可能实现的方法如下:
也就是对于每四位用之前所说的超前加法器,然后这四位产生的结果之间又存在一个
迭代关系。

carry select adder
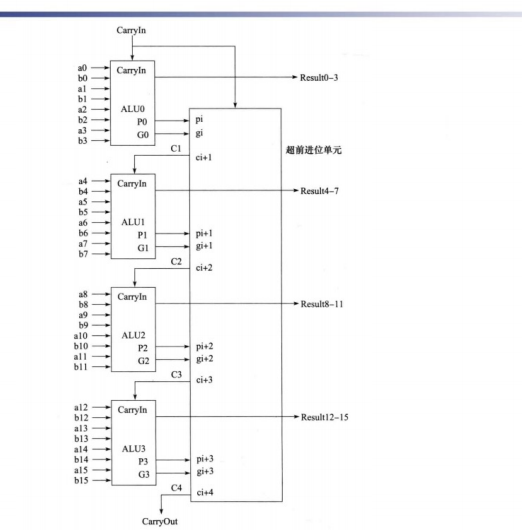
- carry select adder
思路:这就是体现了在chapter中提到的设计中的冗余的思想,将carry为0或1的情况都列出来
再从中选择符合实际的情况
乘法
V1
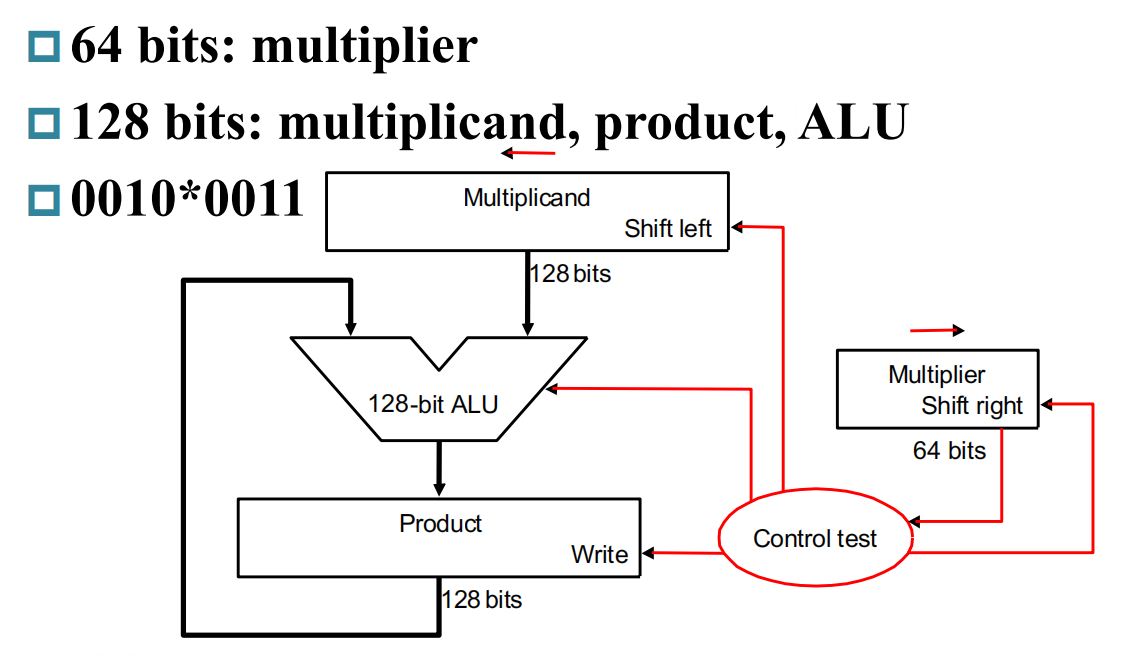
- 解释:最简单的乘法装置就是用一个64位寄存器用来存储乘数,然后每一次进行移位,并同时对被乘数进行移位,如果判断为1,则将现在移位的被乘数加到最终的结果上面(128位alu操作).
V2

- 解释:进行第一次优化,将 Multiplicand 寄存器换为了 64 位,而将位移操作转移到了 Product 寄存器中进行。这里最重要的一点就是,64 位加法只影响 Product 寄存器左侧的 64 位,而之后的右移操作则是 128 位。这样,虽然最低位的结果一开始会被放在 Product 寄存器的第 65 位里,但是在经过 64 次右移之后,它就出现在第一位了。于是,所有的 128 位加法都被 64 位加法替代,实现了加速。
V3
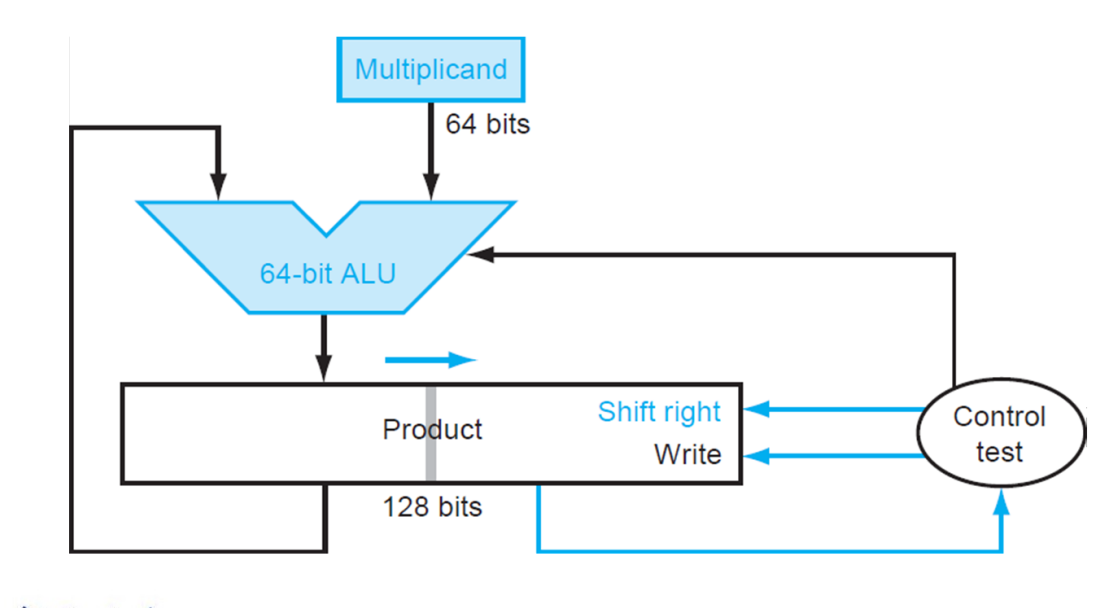
- 解释:直接将 Multiplier 存在了 Product 的低 64 位中。当我们从中取出最低位并经过一次判断后,这一位就不重要了,而恰好 Product 需要右移,就将这一位消除,方便我们下一次从最低位拿出下一个比特。首先,少了一个寄存器,节省了空间;其次,原本需要 Multiplier 寄存器和 Product 寄存器都做右移,现在只需要 Product 寄存器右移即可,减少了一个 64 位右移操作。
faster multiplication
- 将乘数与被乘数展开转化为加法
signed multiplication
除法
V1-division
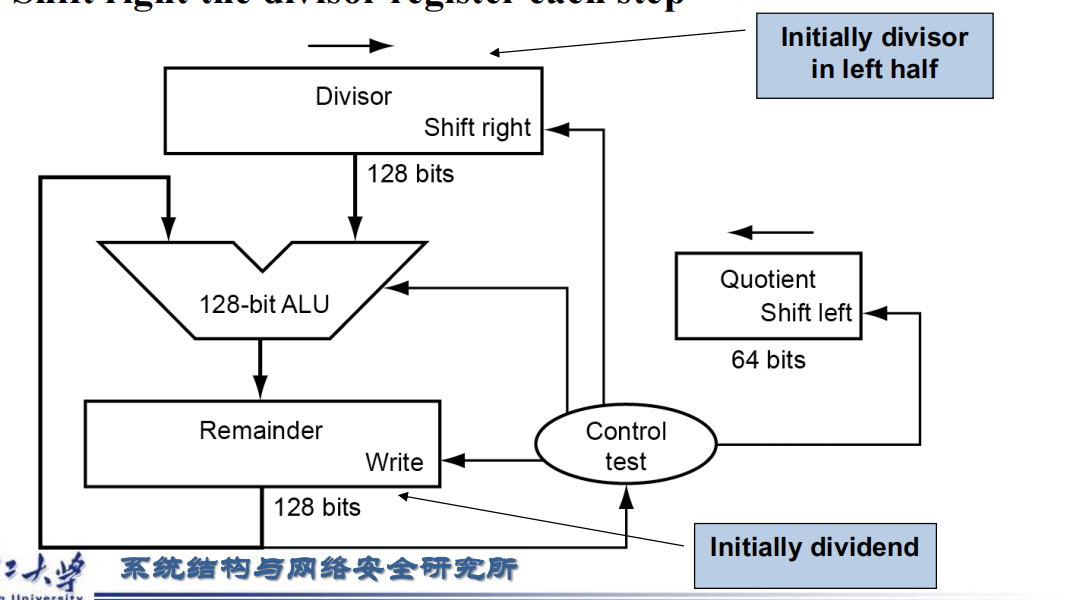
- 解释:最基本的竖式计算。最开始除数放在寄存器的左半部分,被除数放在寄存器的右半部分。然后对除数与被除数作减法,如果结果大于0,则此时的商取1,商移位,被除数也需要移位并且除数继续移位;否则商取0,商移位并且除数继续移位。
V2-division
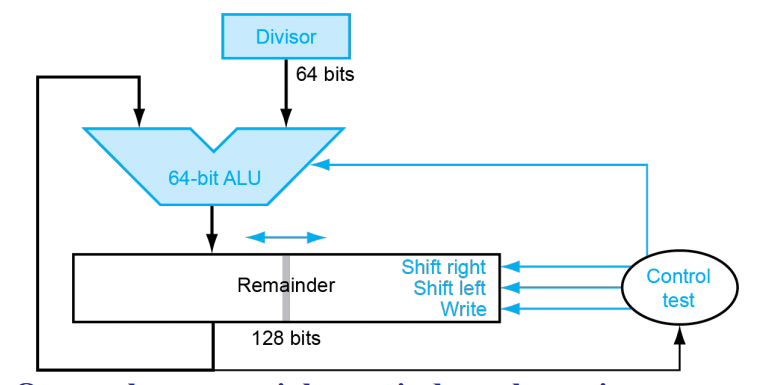
- 解释:想要优化我们上述的除法结构,我们联想到上述加法的V3模式。我们采用类似的结构,64位除数不进行移位操作,而储存被除数的寄存器先放置在左侧,将被除数向左移,(空出来的位置用来放置商),与除数再进行减法。
floating point numbers
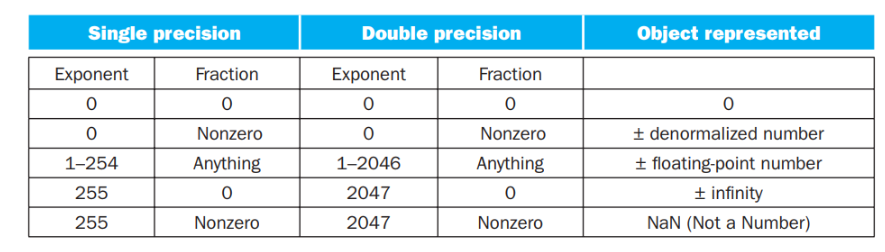
- 对于不同的取值范围对应的表达方式(尤其注意零和正负无穷的表达)
- 下面给出一个浮点数换算的具体例子

floating point addition
- 对齐:小对大进行对齐:为什么是小对大?首先,小对大的过程是在小指数的 fraction 前补 0,可能导致末尾数据丢失;大对小的过程是在大指数的 fraction 后补 0,可能导致前面的数据丢失。在计算过程中,我们保持的精确位数是有限的,而在迫不得已丢去精度的过程中,让小的那个数的末几位被丢掉的代价比大的前几位丢失要小太多了。
- 相加
- 将结果归一化
- 进行舍入操作(可能结果还需要进行归一化)
multiplication
- 将两个 Exponent 相加并 减去一个 bias,因为 bias 加了 2 次
- 将两个 (1 + Fraction) 相乘,并将其规格化;此时同样要考虑 overflow 和 underflow;然后舍入,如果还需要规格化则重复执行
- 根据两个操作数的符号决定结果的符号
准确计算
- 一般的浮点位数后面跟两个bit(guard、round),其目的是让舍入更加精确,所以加减法一般只考虑guard即可。但是对于乘法,如果存在前导零的情况,需要把结果左移的时候,round就会起作用(成为有效位)。
- 一个位叫 sticky bit,其定义是:只要 round 右边出现过非零位,就将 sticky 置 1,这一点可以用在加法的右移中,可以记住是否有 1 被移出,从而能够实现 “round to nearest even”。
chapter4-the processor
4.1 introduction
- CPU performance factors
Instruction count Determined by ISA and compiler
CPI and Cycle time Determined by CPU hardware - We will examine two RISC-V implementations
A simplified version
A more realistic pipelined version - Simple subset, shows most aspects
Memory reference: ld, sd
Arithmetic/logical: add, sub, and, or
Control transfer: beq
overview
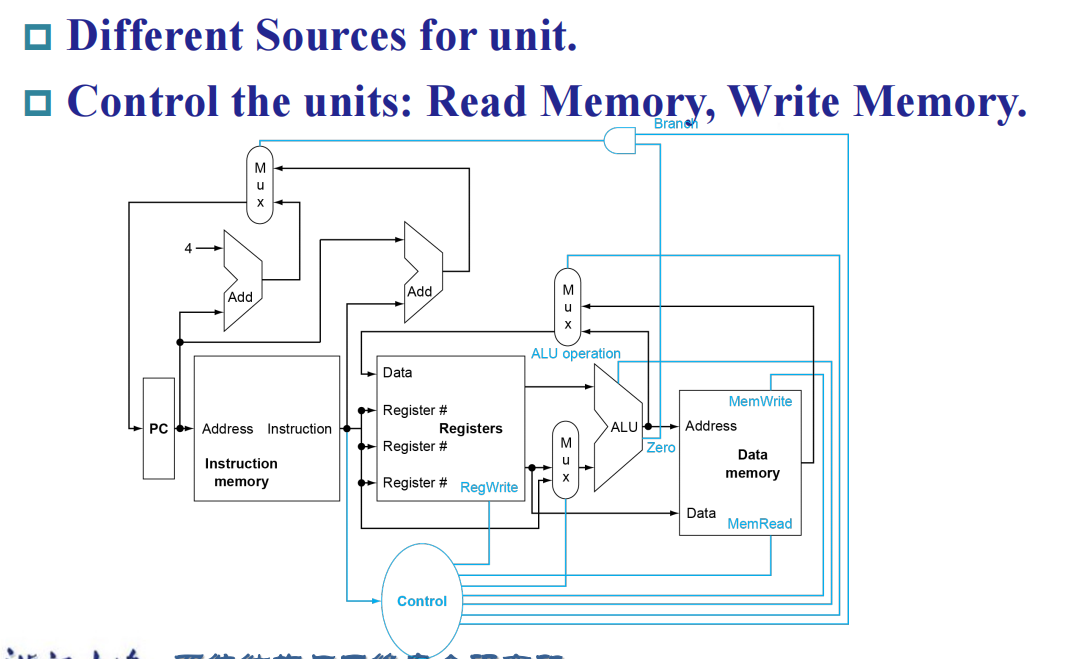
解释:上图中蓝色的线是在原有的overview上面的控制信号
4.2 logic design convention
- 非阻塞赋值:等式右边的值全部被评估完全后,再会赋值给等式左侧。所有赋值操作在当前always块的末尾同时生效。这意味着即使多条赋值语句在代码中是顺序排列的,它们的执行效果是并行的。在时序逻辑中,非阻塞赋值确保了在同一个时钟周期内,所有变量的更新不会互相影响
- 阻塞赋值:右边的值在此刻马上赋给左侧的值。
4.3 building a datapath
instruction execution in Risc-V
- Fetch :
Take instructions from the instruction memory
Modify PC to point the next instruction - Instruction decoding & Read Operand
Will be translated into machine control command
Reading Register Operands, whether or not to use (因为我们每一个指令的格式是固定的) - Executive Control:
Control the implementation of the corresponding ALU operation - Memory access:
Write or Read data from memory
Only ld/sd - Write results to register:
If it is R-type instructions, ALU results are written to rd
If it is I-type instructions, memory data are written to rd - Modify PC for branch instructions
instruction fetch
R-format instructions
所需单元如下:
- Read two register operands
- Perform arithmetic/logical operation
- Write register result
load/store instrutions
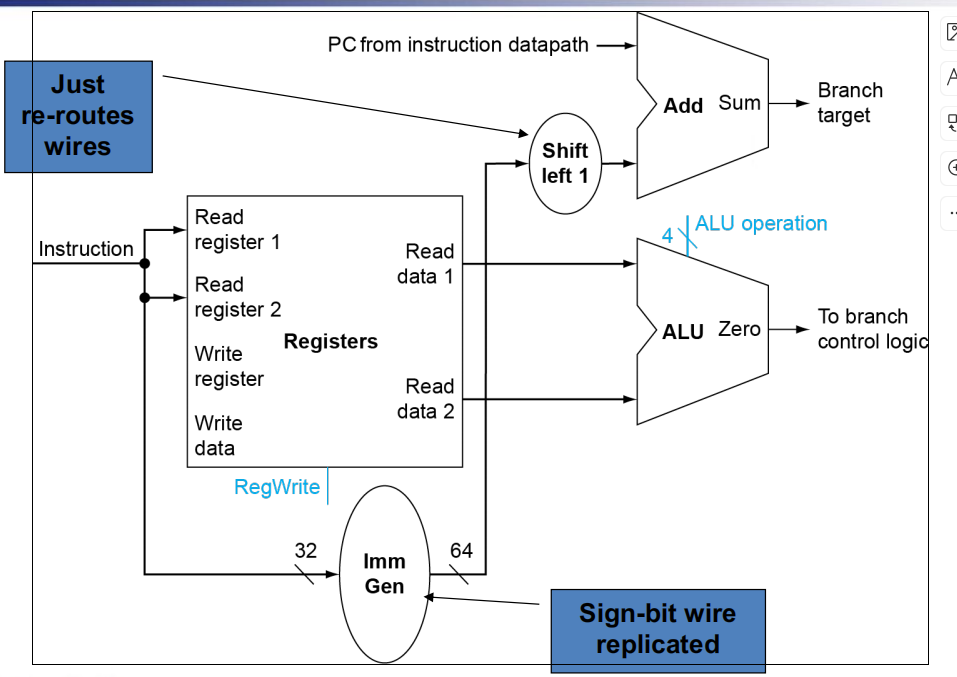
branch instructions
- Read register operands
- Compare operands
Use ALU, subtract and check Zero output (beq) - Calculate target address
Sign-extend displacement
Shift left 1 place (halfword displacement)(默认最后一位为零,则需要左移进行补零)
Add to PC value
full datapath
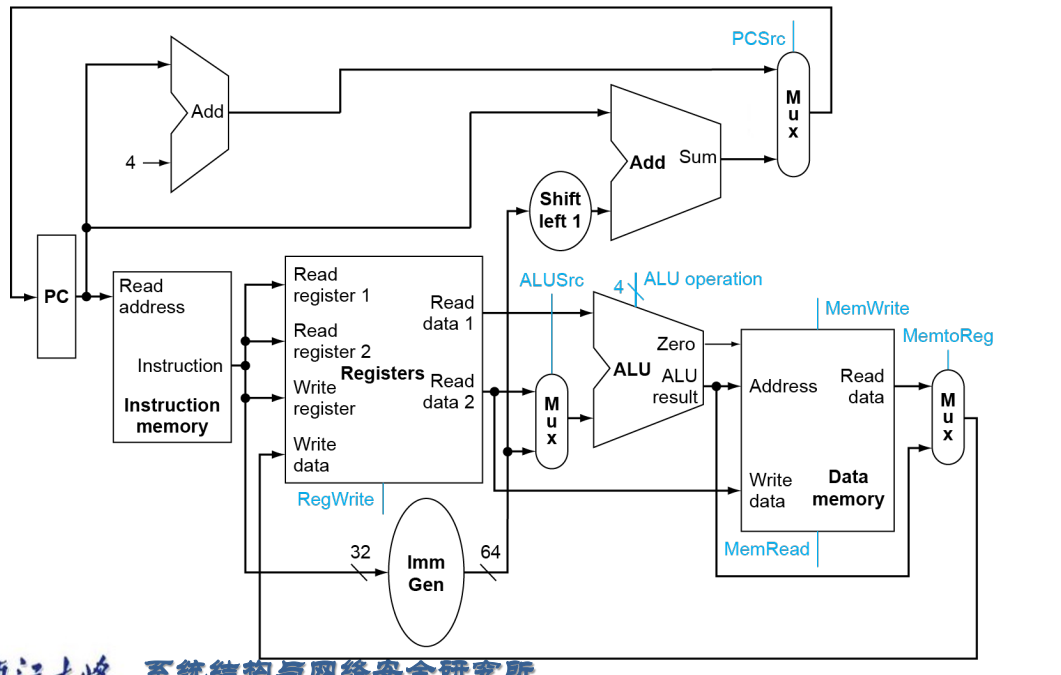
4.4 a simple implementation scheme
7 controller
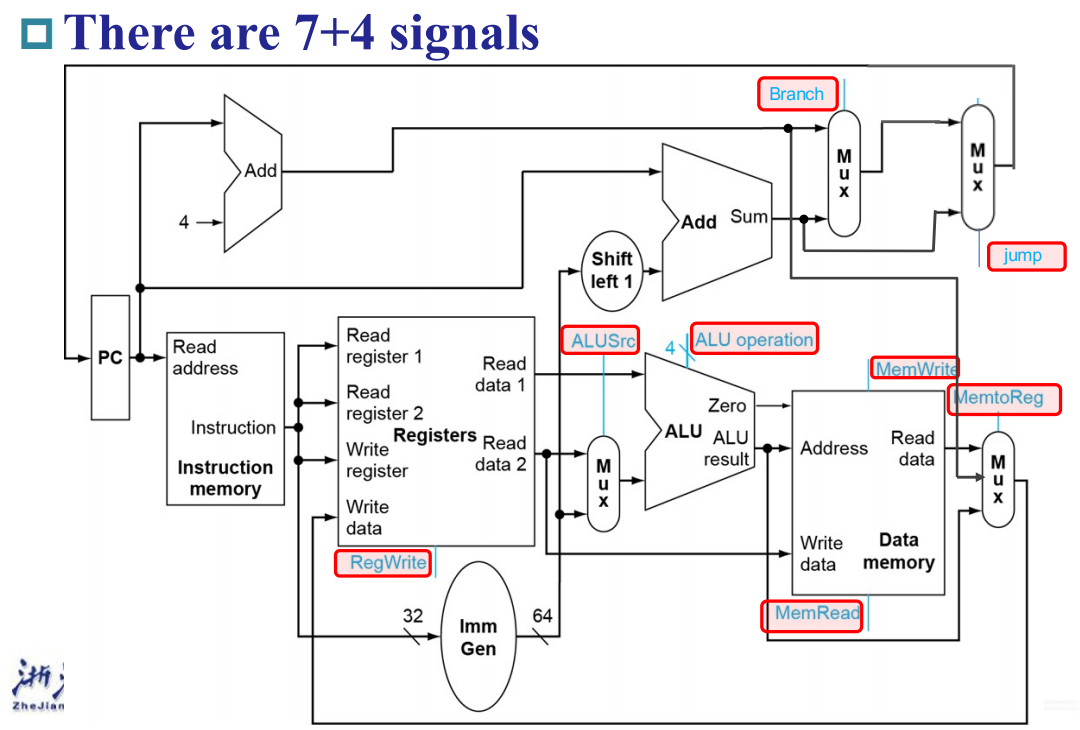
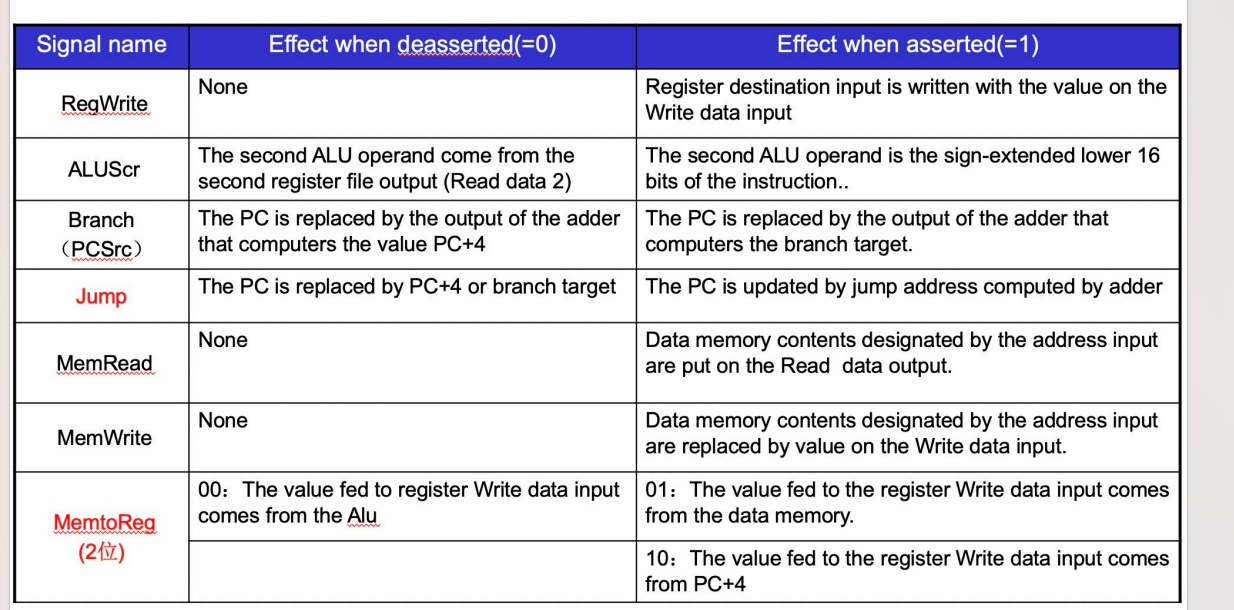
- 具体七个控制逻辑的意义
![seven]()
4.5 an overview of the pipeline
risc-v pipeline
Five stages, one step per stage
- IF: Instruction fetch from memory
- ID: Instruction decode & register read
- EX: Execute operation or calculate address
- MEM: Access memory operand
- WB: Write result back to register
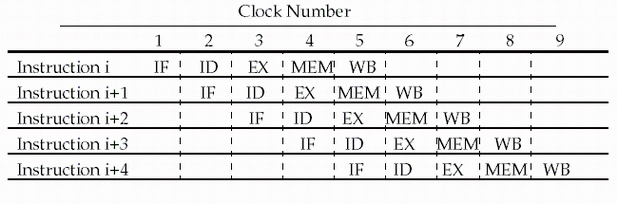
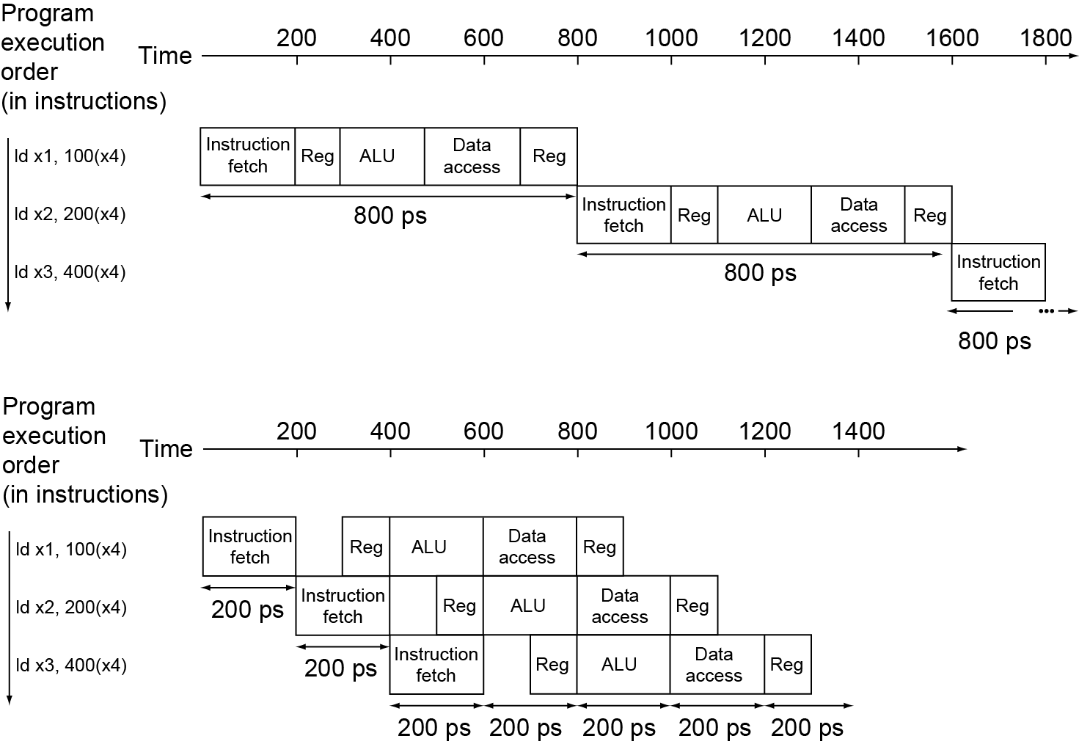
Note:CPI is decreased to 1, since one instruction will be issued (or
finished) each cycle.Speedup due to increased throughput but Latency (time for each instruction) does not decrease
risc-v pipeline 优势
- All instructions are 32-bits
Easier to fetch and decode in one cycle
c.f. x86: 1- to 17-byte instructions - Few and regular instruction formats
Can decode and read registers in one step - Load/store addressing
Can calculate address in 3rd stage, access memory in 4th stage
hazard(竞争)
strutrue hazard
data hazard
control hazard
解决hazard
解决structure hazard
- 产生:前一个指令在ID阶段时会使用其在IF阶段读出的指令内容,但是此时后一个指令已经运行到IF阶段并读出内容,为了解决控制信号的冲突,我们实际上会在每两个stage之间使用寄存器保存这些内容。
- 解决
![structrue]()
解释:我们现在在两个stage中的竖条条就是pipline registers。但是还需要关注datapath中两个从右往左的path,一个是wb阶段写回数据(在这个情况下,write register要随着其他控制信号向下传递),一个是MEM阶段判断是否发生跳转。
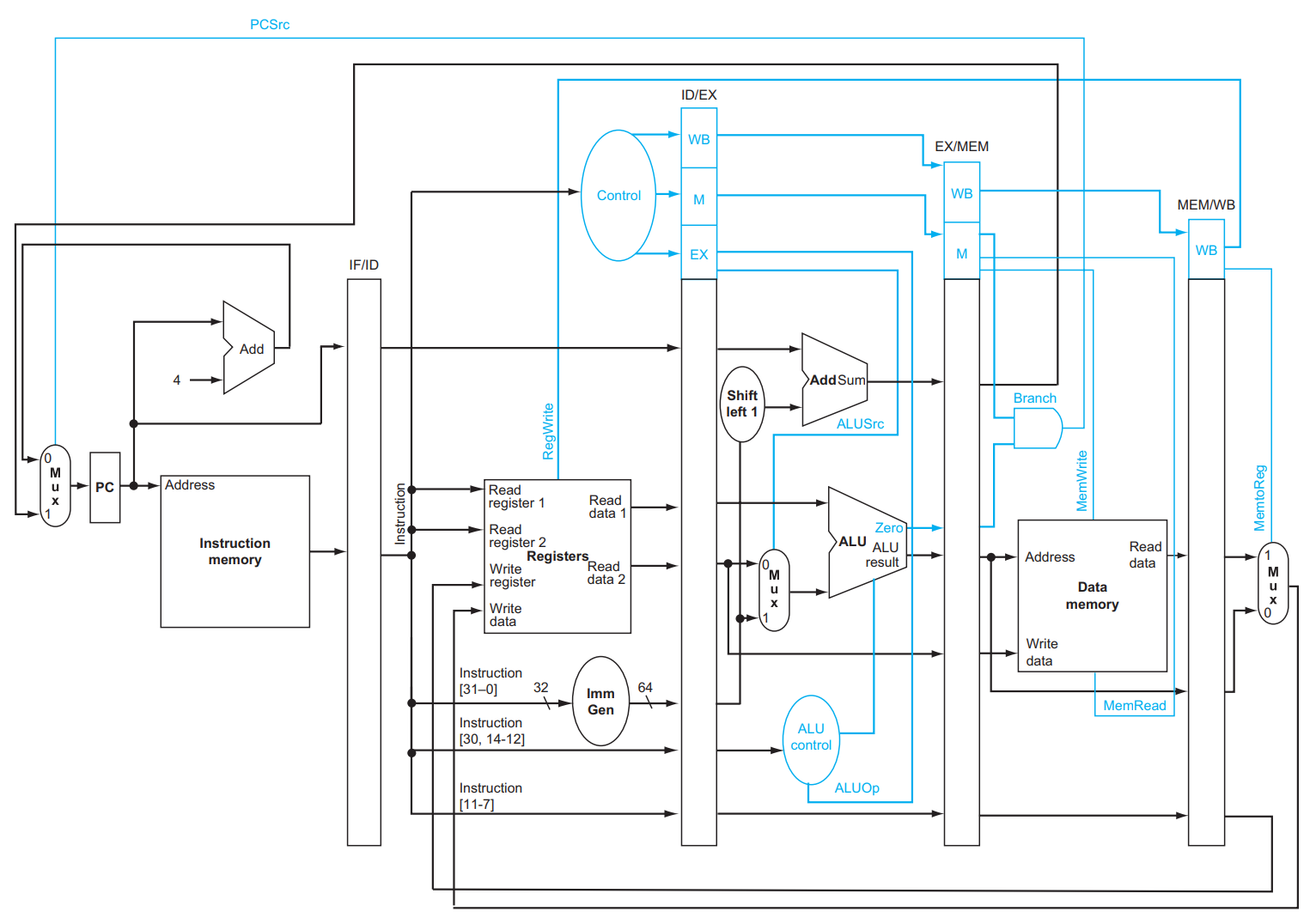
解决data hazard
- forwarding
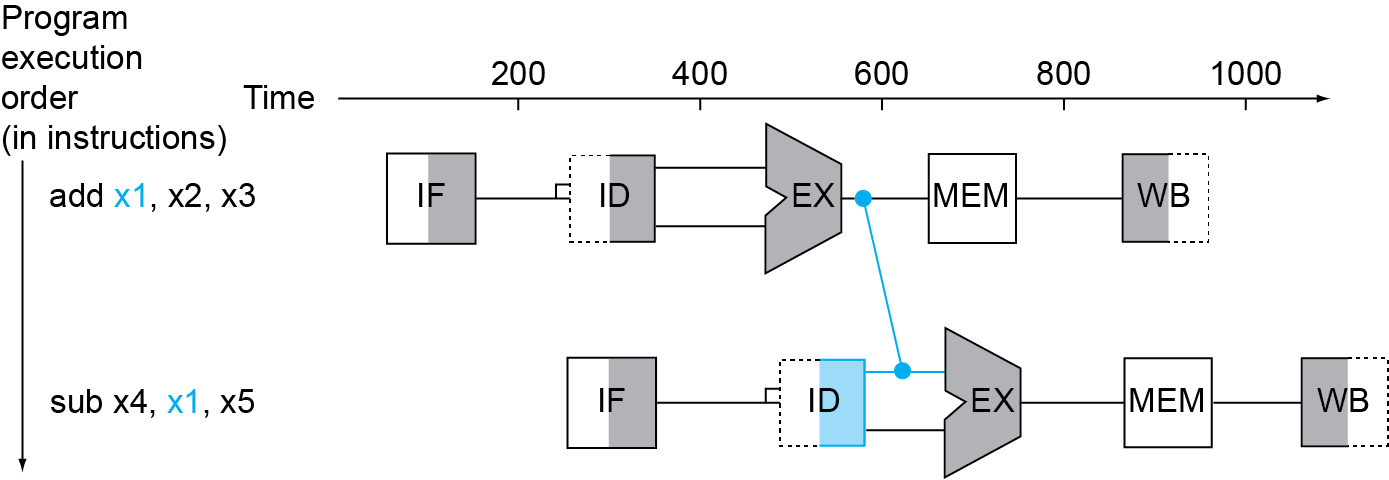
- load-use data hazard
如果是load我们所需要的数据就没有在EX后面产生,而是在MEM阶段产生,则我们可能再经过一个bubble,再将MEM的输出数据通过旁路转发给EX的输入
- 给定一段c语言与相对应的指令,计算出需要的时钟周期
ld x1, 0(x0)
ld x2, 8(x0)
stall
add x3, x1, x2
sd x3, 24(x0)
ld x4, 16(x0)
stall
add x5, x1, x4
sd x5, 32(x0)
13 cycles
相同的c语言代码但是改进的risc-v代码
ld x1, 0(x0)
ld x2, 8(x0)
ld x4, 16(x0)
add x3, x1, x2
sd x3, 24(x0)
add x5, x1, x4
sd x5, 32(x0)
11 cycles
解决control hazard
Branch prediction
更长的流水线无法在早期确定分支结果
停顿惩罚变得不可接受预测分支结果
仅在预测错误时停顿在 RISC-V 流水线中
可以预测分支未被采取
在分支后立即获取指令,无需延迟
4.6 RISC-V pipeline datapath
pipline registers
- note:注意register number在流水线中需要随着进程往下传导,否则操作的register不再是原来的register
4.7 data hazard
判断何时出现 data hazard
Data hazards when
1a. EX/MEM.RegisterRd = ID/EX.RegisterRs1
1b. EX/MEM.RegisterRd = ID/EX.RegisterRs2
2a. MEM/WB.RegisterRd = ID/EX.RegisterRs1
2b. MEM/WB.RegisterRd = ID/EX.RegisterRs2But only if forwarding instruction will write to a register!
EX/MEM.RegWrite, MEM/WB.RegWriteAnd only if Rd for that instruction is not x0
EX/MEM.RegisterRd ≠ 0,
MEM/WB.RegisterRd ≠ 0
解决double data hazard
- Consider the sequence:
add x1,x1,x2
add x1,x1,x3
add x1,x1,x4 - Both hazards occur(满足前面我们所说的a和b两种情况)
Want to use the most recent - Revise MEM hazard condition
Only fwd if EX hazard condition isn’t true - 具体条件代码
if (MEM/WB.RegWrite
and (MEM/WB.RegisterRd ≠ 0)
and not(EX/MEM.RegWrite and (EX/MEM.RegisterRd ≠ 0)
and (EX/MEM.RegisterRd = ID/EX.RegisterRs1))
and (MEM/WB.RegisterRd = ID/EX.RegisterRs1)) ForwardA = 01
解释:加粗部分是为了避免上一个EX/MEM也满足条件,从而选择上上级的MEM/WB进行旁路传输,而如果上一级的EX/MEM满足条件,则选择上一级的EX/MEM进行旁路传输。
hazard detection
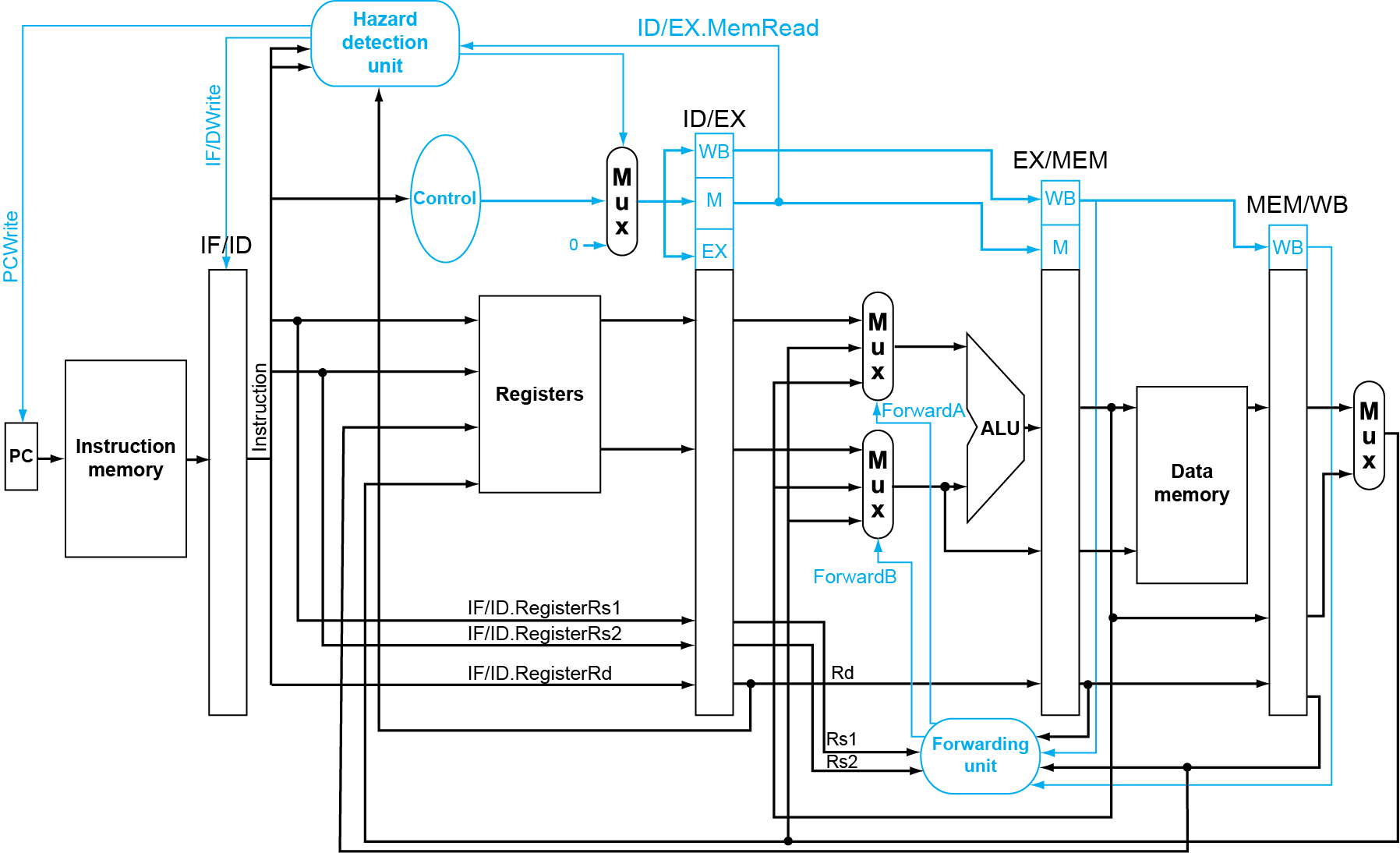
解释:我们主要解释图片的hazard detection unit,这个单元就是为了解决load-use hazard,这个单元的输入分别为相应位置的rs1,rs2,rd,ID/EX.MemRead,而向右的输出如果存在hazard则进行赋零,向左的两个输出就是如果存在hazard则pc端先暂停一下等待一个时钟周期再往下进行(为了空泡的产生)。
4.8 Branch Hazards
dynamic branch prediction
calculating the branch target
- Even with predictor, still need to calculate
the target address
1-cycle penalty for a taken branch - Branch target buffer
Cache of target addresses
Indexed by PC when instruction fetched
If hit and instruction is branch predicted taken, can fetch target immediately
4.10 instruction-level parallelism
multiple issue(多发)
risc-v with static dual issue
- 对于双发问题,在packets中我们常常把alu/branch 与load/store指令放在一个包中
- 因为这两个类型的指令所使用的结构大多不相同,能够有效平衡资源利用。
loop unrolling
- 循环展开:比如将一次循环做一次的程序改为一次循环我们可以做多次,这样在双发系统中能让空泡减少,提高效率。
- ex
1 | |
dynamic scheduling
- ex
ld x31,20(x21)
add x1,x31,x2
sub x23,x23,x3
andi x5,x23,20
则可以将sub先开始再执行add
4.11 exception
定义
- 广义:exception
- 狭义:exception(内部处理器) interrupt(外部)
handling exceptions
- save PC of offending instruction
- save indication of the problem
- jump to handler
Assume at 0000 0000 1C09 0000hex,再跳到cause 寄存器,再跳转到程序发生异常的地方
an alternate mechanism
一些寄存器
- mepc(异常pc地址存储器)
- 发生exception:mepc<-pc
- 发生interrupt:mepc<-pc+4
- 低的两位永远是0
- mcause(异常原因)
- 异常原因的优先级:External interrupt > Software interrupt > Timer interrupt
Risc-v中断处理-进入异常
- RISC-V处理器检测到异常,开始进行异常处理:
- 停止执行当前的程序流,转而从CSR寄存器mtvec定义的PC地址开始执行;
- 更新机器模式异常原因寄存器:mcause
- 更新机器模式中断使能寄存器:mie
- 更新机器模式异常PC寄存器: mepc
- 更新机器模式状态寄存器: mstatus
- 更新机器模式异常值寄存器: mtval
Risc-v中断处理-异常返回
- 机器模式下退出异常(MRET)
- 程序流转而从csr寄存器mepc定义的pc地址开始执行
- 同时硬件更新csr寄存器机器模式状态寄存器mstatus
- 寄存器MIE域被更新为当前MPIE的值:mie ← mpie
- MPIE 域的值则更新为1: MPIE ← 1
流水线中的exception
exception example
- 此时出错的指令在EX阶段,则将自己flash掉,并且前面已经进入执行的两个指令都flash掉,所以在下一个时钟周期,会出现3个bubble,并开始执行handler 指令。
- Handler:1C090000 sd x26, 1000(x10)
1c090004 sd x27, 1008(x10)
multiple exceptions
- 当出现多个异常时,最简单的方法就是顺序处理。
- 而在复杂的流水线中我们考虑的东西更多。
Chapter5-Large and Fast:Exploiting Memory Hierarchy
5.1 Memory technologies
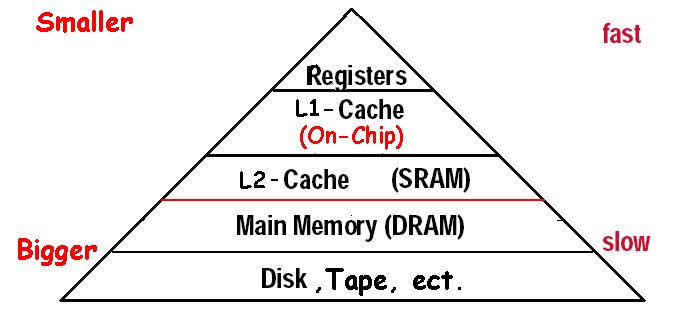
5.2 Memory hierarchy
- 时间局部性:最近经常用的就放在离cpu近的地方
- 空间局部性:离最近常访问的元素较近的也可能被经常访问,也放在离cpu近的地方
taking advantage of locality
- 所有东西都存在disk中
- 将最近常访问的和离它们最近的从disk复制到较小的DRAM中
- 将最近常访问的和离它们最近的从DRAM复制到较小的SRAM中
![jiegou]()
some important items
- Block(复制单元)
- 如果被访问的数据出现在上层
- hit:上层满足权限
- hit ratio命中率:命中/访问
- 如果没有被访问的数据
- miss:the cpu accesses the upper level and fails.再把block从lower level复制而来,再将此时的上层数据提供给cpu
- miss ratio=1-hit ratio
- time taken:miss penalty
exploiting memory hierarchy
5.3 the basics of cache
direct mapped cache
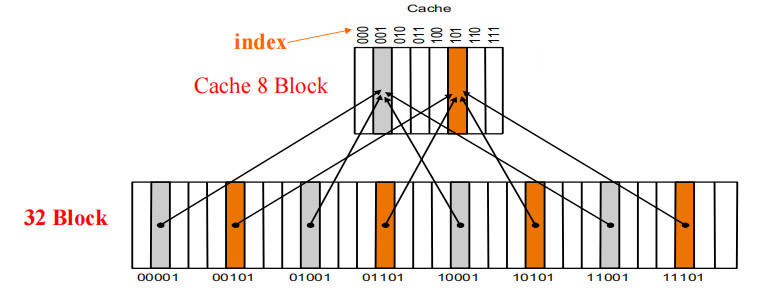
- 一种cache结构,其中每个存储地址都映射到cache中的确定位置
- 使用以下方法得到index
- (块地址)mod(cache中的数据块数量)
- 若cache中有2^n个数据块,那么索引为主存块地址的最低n位
- 那么我们怎样确定在cache中编号到底是哪个block呢?—tag
- 确定这个block有效–valid bit
example
- 32位主存地址,4-block cache,1-word Block
- 4-block 则索引位index为两位(字节偏移量前两位)
- 且是1-word Block 则里面有4个byte,则字节偏移量(m+2)为两位(最后两位)
- 则另外的28位为tag
- 则我们成功把主存地址剥离三个部分!
- 此后我们就能进入cache找到对应的index再进行tag的比对,valid bit是否为1,如果都满足就可以读数据了
- total number of bits:2^n*(block size+tag size+valid field size)
example2
- How many total bits are required for a direct-mapped cache 16KB(总的数据大小) of data and 4-word blocks, assuming a 32-bit address?
handleing cahce hits and misses
read
write
- write hits
- write-back:write back data from the cache to memory later(Fast!)
- write-through:writes always update both the cache and the memory
- write misses
read the entire block into the cache, then write the word
buffer
- 写缓冲,保存着等待写回主存的数据,数据写入cache的同时也写入写缓冲中,之后处理器继续执行。通常用于后面会提及的write-through策略中。
Deep concept in Cache
- Q1: Where can a block be placed in the upper level?
(Block placement)- Fully Associative(Block can go anywhere in cache.)
- Set Associative(Block can go in one of a set of places in the cache.;A set is a group of blocks in the cache.Block address MOD Number of sets in the cache
;If sets have n blocks, the cache is said to be n-way set associative.) - Direct Mapped(Usually address MOD Number of blocks in cache)
- Q2: How is a block found if it is in the upper level?
(Block identification)
Tag/Block- 对于fully associated cache,index=0.(所有的block都可以访问);对于主关联,index的大小取决于主关联的set;对于direct mapped,index select the block
- 以下为根据主存地址寻找cache中的block的三种方法
- Q3: Which block should be replaced on a miss?
(Block replacement)- Random, LRU,FIFO(我们需要注意因为这种原则,也可以大大降低miss rate)
- 因为direct mapped,则每个对应的主存地址只能去向cache中指定的位置,则不存在位置的冲突情况。我们下面的替换方法(本质上都是增加cache命中率)主要针对全关联与主关联。
- random replacement-randomly pick any block
- Least-recently used(对于两路主关联增加一位就可以)
- first in,first out
- Q4: What happens on a write?
(Write strategy)
针对write hit
- Write Back or Write Through (with Write Buffer)
- write-through:在写操作时,数据不仅写入缓存,同时也立即写入主存;Cache control bit: only a valid bit; memory (or other processors) always have latest data
- write-back:在写操作时,数据只写入缓存,而不立即写入主存。当缓存行被替换出去时,才会将修改后的数据写回主存;Cache control bits: both valid and dirty bits;much lower bandwidth, since data often overwritten multiple times
- write allocate(针对write-back的miss): The block is loaded into the cache on a miss before anything else occurs。说一下人话:将block拿到cache里面以后再进行写入操作。
- write around(针对write-through的(miss):The block is only written to main memory;It is not stored in the cache.就直接在memory里面写,没必要拿进cache里面。
Larger blocks exploit spatial locality
designing the memory system to support cache
5.4 Measuring and improving cache performance
- Average Memory Assess time = hit time + miss time
= hit rate × Cache time + miss rate ×memory time
= 99% × 5 + (1-99%) × 45 =5.5ns
mearsing cache performance
- read-stall cycles=$\frac{Read}{Program}$ Read miss rate*Read miss penalty
- write-stall cycles=$\frac{Write}{Program}$Write miss rate*Write miss penalty$+Write buffer stalls(write-through)
- 在绝大多数write-back cache organizations,the read and write miss penalties are the same
- 如果我们忽略write buffer stalls,Memory-stall clock cycles=$\frac{Memory accesses}{Program}$Miss rate*Miss penalty
=$\frac{instructions}{Program}$ $\frac{Misses}{instructions}$Miss penalty - 但是我们计算时需要注意,发生miss不仅可能针对instructiuon会发生miss,对于data(当我们进行load与store操作时)也会发生miss,因为这两个步骤都涉及我们的内存。
- Memory-stall clock cycles=$# of instructionsmiss ratiomiss penalty$
solution
5.5 virtual memory(硬盘与Main memory的转换)
- 作用:Efficient and safe sharing of memory among
multiple programs.Remove the programming burdens of a small,limited amount of main memory. - 虚拟地址与物理地址的转换
- 在虚拟地址的作用下,程序的地址看起来是连续的,programme relocation
pages: virtual memory blocks
- page faults:执行程序还不在main memory里面,则我们需要把程序从disk加载到main memory里面。而这个单元就是page。注意我们使用write back。
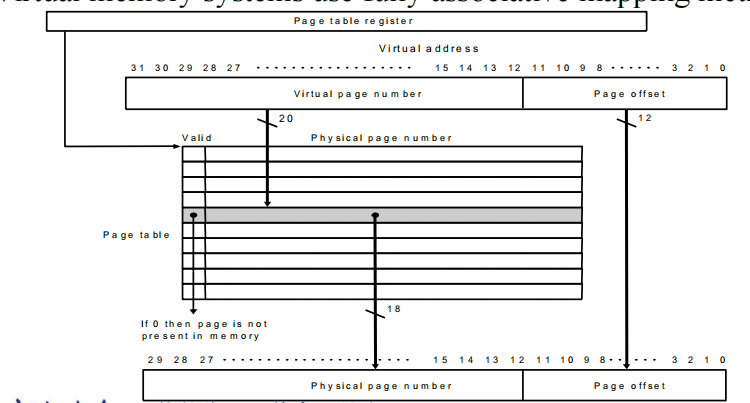
- page tables(virtual to physical address)
- 放在内存里面
- Each Entry in the table contains the physical page number for that virtual pages if the page is current in memory
- Page table, Program counter and the page table register, specifies the state of the program. Each process has one page table. (Process switch? )
- 每一个programme 都有自己的page table,并且采用fully associative mapping method
- page的映射:
![page]()
- page offset:表示了每一个page的大小,常常经过映射以后physical address中的page offset大小与virtual address中的page offset大小一致。
- virtual page number:表示每一个page table中的行数(page entries的数量)
- 我们的映射其实就是通过page table把virtual page number映射到physical page number
- 如上图所示,每个 entry 中包含了一个 valid bit 和 physical page number。如果 valid bit = 1,那么转换完成;否则触发了 page fault,handle 之后再进行转换。
- page faults:
- When a page fault occurs, the OS will be given control through exception mechanism.
- Making Address Translation Fast
- The TLB acts as Cache on the page table.
- A cahce for address translations:translation look aside buffer.
TLB,page tables,cache
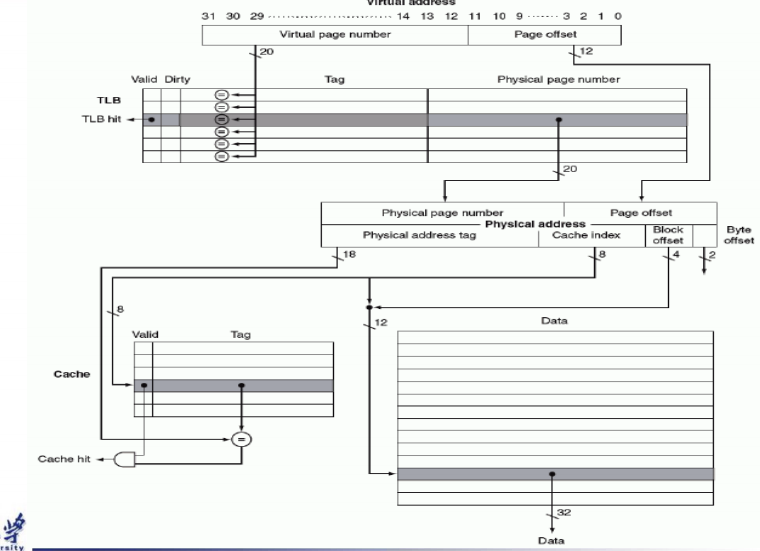
- Three different types of misses:TLB miss,page table miss,page miss
Modern Svstems
- instructions的TLB和数据的TLB需要分开,因为如果放在一起,因为instructions的地址的连续性,而data更离散,可能导致命中率下降
Chapter6-I/O
6.1 Introduction
三个特点
- Behavior
- Partner
- Data rate(数据可以在I/O设备和主存储器或处理器之间传输的峰值速率)
I/O 性能的评估
- I/O性能一般评估较为麻烦但是可以从以下几个方面评估:
- 吞吐量:The number of operations per unit time。在这个评估准则下I/O的bandwidth便很重要。
- Response time
- both throughput and response time
Amdahl’s Law
- 思想:顺序部分限制加速,我们采取并行的思想
- 例子:有100个处理器,我们想要加速到原来的90倍
假设现在我们并行的程序占比为F,则我们有:$\frac{1}{(1-F)+\frac{F}{100}}=90$,解得F=0.999
6.2 Disk storage and dependability
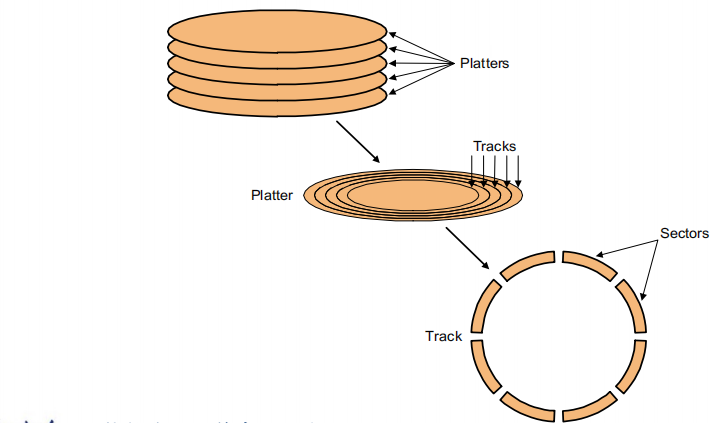
The organization of hard disk
- platters(盘): disk consists of a collection of platters, each of which has two recordable disk surfaces
- tracks: each disk surface is divided into concentric circles(同心圆)
- sectors: each track is in turn divided into sectors, which is the smallest unit that can be read or written
![disk1]()
To access data of disk
- 寻道时间(Seek):The time required to move the head to the correct track.(通常是3-14 ms)
- Rotational latency:The time required to rotate the head to the correct position on the track.
ex:For 5400RPM(每分钟的旋转数):Average rotational latency=$\frac{0.5 rotation}{5400RPM}$ - Transfer:传输sector的时间
ex:For 512B/sector,50MB/s,Transfer time=$\frac{0.5KB}{50MB/sec}$ - Disk controller:控制disk与内存的transfer
- Access Time=Seek time+Rotational latency+Transfer+Disk controller time
Measure
- MTTF 平均无故障时间
三种提高MTTF的方式:- fault avoidance(从发生端减少)
- fault tolerance(运用冗余的思想)
- fault forcasting(预测)
- MTTR 平均修复时间
- MTBF=MTTF+MTTR 平均故障间隔时间
- Availablity=$\frac{MTTF}{MTTF+MTTR}$
Use Arrays of Small Disks?
- 想要通过用小的硬盘来搭建一个大的硬盘。
- 但是这样大硬盘的可靠性会下降
- 考虑使用RAID(磁盘冗余阵列)技术,raid0(Non-redundant striped),raid1,raid5,raid6。当出现问题时数据从redundant disk中恢复。
RAID
- RAID 0:Non-redundant striped,但是因为是用小磁盘阵列来搭建大磁盘所以large accesses是提升了的。
- RAID 1:Disk Mirroring/Shadowing
- Very high availability can be achieved(每一个磁盘的冗余都是被完全从这个磁盘复制的)
- Bandwidth sacrifice on write:Logical write = two physical writes;Reads may be optimized
- Most expensive solution: 100% capacity overhead(支出)
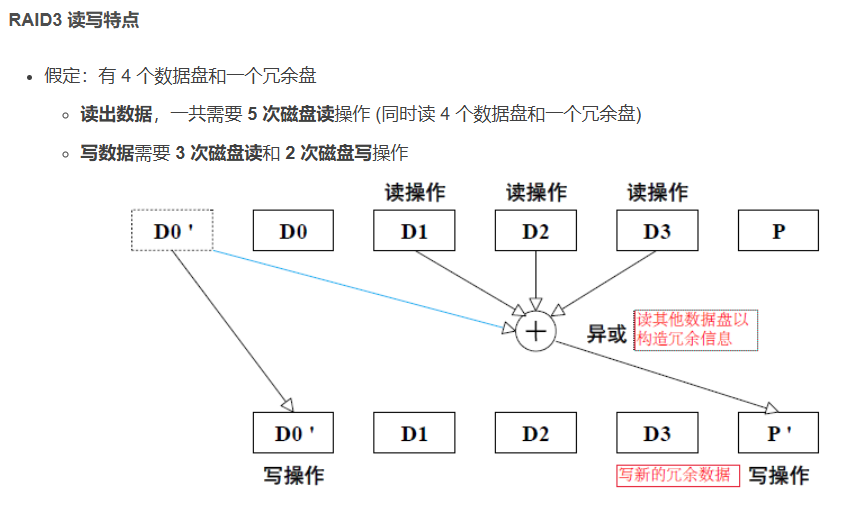
- RDID 3:Bit-Interleaved Parity Disk
- 奇偶校验:一旦一个磁盘出现故障,则可以根据奇偶校验恢
复。 - 但是单纯从奇偶校验的逻辑无法判断哪个盘坏掉。
- 但是等待整个盘的校验是性能较低的,这给了我们对于后面raid设计的启示,让每一个setcor都能catch error,这样我们的性能就不会被parity disk约束。
- raid3的读写特点
![raid3]()
- 奇偶校验:一旦一个磁盘出现故障,则可以根据奇偶校验恢
- RAID 4:相对于RAID 3,每个盘都加上一个deduction,可以直接判断每个磁盘坏没坏,从而不用使用奇偶校验判断。
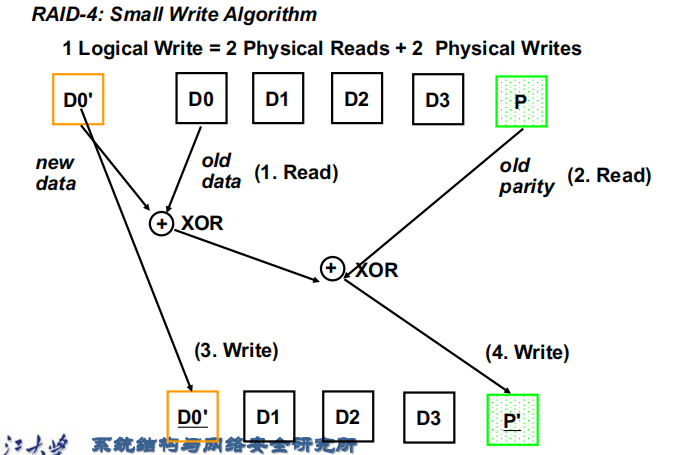
- Small writes are limited by Parity Disk: Write to D0, D5 both also write to P disk。下面是一个small write的例子:
![smallwrite]()
- 而对于large write,我们几乎访问所有磁盘则其代价与RAID3差别不大。
- 就如前面提到的,raid4对于small write(虽然读操作已经优于RAID3)并不是表现很好,因为我们不能同时实现两个small write操作,因为都需要写入到P盘中。
- Small writes are limited by Parity Disk: Write to D0, D5 both also write to P disk。下面是一个small write的例子:
- RAID 5:
- 相对于RAID 4的改进,parity盘不再固定,而是分布在每行的不同位置,则我们的许多small write能够同时写入。
- RAID 6(P+Q Redundancy)
6.3 Buses and Other Connections between Processors Memory,and I/O Devices
Bus Basics
- 一个bus有两种线:Control lines and data lines
- Bus transaction:input and output
Types of Buses
- processory-memory:short high speed,custom design
- backplane:high speed,often standardized
- I/O:lengthy,different devices,standardized
同步总线与异步总线
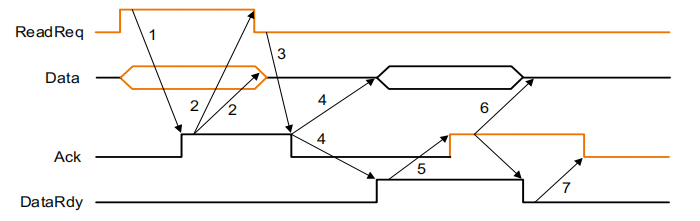
- Asynchronous bus : don’t use a clock and instead
use handshaking![yibu]()
- 当内存看到ReadReq行时,它从数据总线读取地址,开始内存读取操作,然后提高Ack,告诉设备已经看到了ReadReq信号
- I/O设备看到Ack行很高,并释放ReadReq数据线。
- Memory sees that ReadReq is low and drops the Ack line
- 当内存准备好数据时,它会将数据放在数据线上,并引发DataRdy
- I/O设备看到DataRdy信号,从总线中读取数据,并通过提高ACK发出它有数据的信号
- The memory sees Ack signals, drops DataRdy, and releases the data lines.
- Finally, the I/O device, seeing DataRdy go low, drops the ACK line, which indicates that the transmission is completed
- 以上的七个步骤为用异步的握手协议从内存读取一个字到I/O设备的过程
- 同步总线与异步总线性能分析:
当我们算带宽时对于异步总线一定要按照这七个步骤进行计算。
//后面的内容就形成a4了吧
Bus Arbitration
- 我们需要bus master启动和控制所有的总线请求
- two factors决定哪个设备占用总线
- 优先级
- fairness
6.4 Interfacing I/O TO the memory
- I/O 系统的三个特性
- 由使用处理器的多个程序共享。
- 经常使用中断来传达有关I/O 操作。
- I/O 设备的低级控制很复杂
- 需要三种类型的通信:
- 操作系统必须能够向 I/O 设备发出命令。
- 设备必须能够在 I/O 设备
已完成操作或遇到错误通知 OS。 - 必须在内存和 I/O 设备之间传输数据
给命令给I/O
直接采用对I/O进行映射到相应的地址,然后就可以直接使用指令
采用特殊的I/O指令
与处理器进行交流
- 轮询(Polling):处理器定期检查状态。位查看是否是下一次 I/O 操作的时间。
- Interrupt:当 I/O 设备想要通知时处理器已完成某些操作,或者需要注意,它会导致处理器打断。
- 显而易见,用中断相对于polling,只需要在需要的地方介入,
- DMA(直接内存访问):设备控制器。将数据直接传输到内存或从内存中传输数据,而无需涉及处理器
- 处理器通过提供一些
信息,包括设备的身份、operation、作为源的内存地址或要传输的数据的目的地和数量要传输的字节数。 - DMA 在设备上启动操作并仲裁
对于总线。如果请求需要多次转移在总线上,DMA 单元生成下一个内存地址并启动下一次传输。 - DMA 传输完成后,控制器
中断处理器,然后检查处理器是否
发生错误。
- 处理器通过提供一些
期末
- datapath中的控制信号注意memory write和register write不能随便设置为no care,因为总线上很有可能有乱七八糟的值。
- 流水线怎么处理hazard的方式是有假设的。